hgkohm
-
Total de itens
1 -
Registro em
-
Última visita
Sobre hgkohm

hgkohm's Achievements
0
Reputação
-
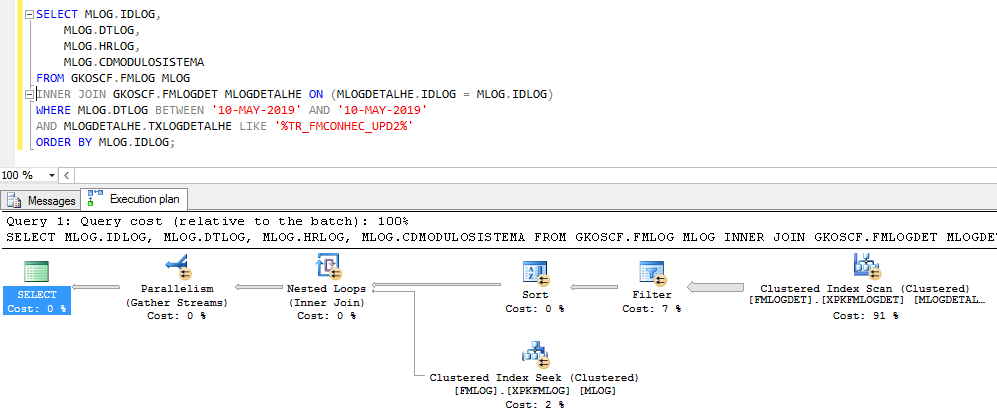
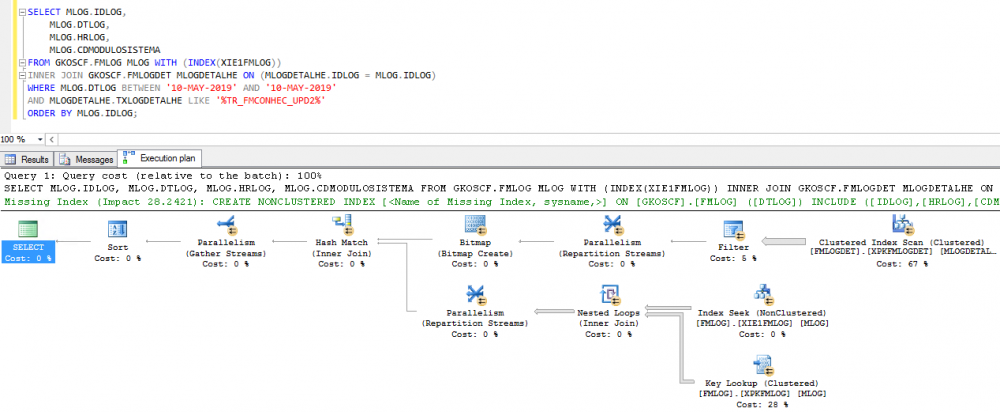
Pessoal, Estou com um problema de performance em uma das consultas nos bancos de dados SQL Server. Tenho o cenário descrito abaixo e gostaria de saber se alguém já se deparou com este problema ou se saberia o motivo. A query (abaixo) possui filtros, onde o campo de data DTLOG tem índice e o campo TXLOGDETALHE não possui índice e seu tipo de dados é TEXT. Ocorre a seguinte situação: Pelo plano de execução identificamos que o otimizador opta por não utilizar o índice existente para o campo de data (DTLOG) e com isso faz um FULLSCAN na segunda tabela do JOIN (FMLOGDET) que possui milhões de registros usando a PK (conforme imagem abaixo). Mesmo forçando o otimizador usar o índice da coluna DTLOG, ele continua fazendo o FULLSCAN pela PK na tabela FMLOGDET e com isso a performance continua ruim. DÚVIDA: Porque mesmo filtrando por apenas 1 dia, o otimizador continua fazendo o FULLSCAN na tabela (FMLOGDET), onde colocamos o LIKE, e não utiliza o índice criado para o campo DTLOG da tabela (FMLOG), diminuindo assim o esforço? Pela lógica, se ele filtrasse pela data primeiro, teria uma quantidade de registros menor para o segundo filtro e com isso o custo seria dentro do esperado. Mas ele executa o caminho inverso (as estatísticas estão atualizadas). Uma observação, quando colocamos no filtro DTLOG, uma data maior que o dia atual, o retorno da query é instantâneo e no plano mostra que o índice é utilizado. QUERY: SELECT MLOG.IDLOG, MLOG.DTLOG, MLOG.HRLOG, MLOG.CDMODULOSISTEMA FROM GKOSCF.FMLOG MLOG INNER JOIN GKOSCF.FMLOGDET MLOGDETALHE ON (MLOGDETALHE.IDLOG = MLOG.IDLOG) WHERE MLOG.DTLOG BETWEEN '10-MAY-2019' AND '10-MAY-2019' AND MLOGDETALHE.TXLOGDETALHE LIKE '%TR_FMCONHEC_UPD2%' ORDER BY MLOG.IDLOG; Os teste e configurações abaixo foram realizados, mas não obtivemos sucesso: 1. Executamos a mesma query nas versões 2012, 2014 e 2016 com SP atualizados, mas em todas as versões apresentou o mesmo caso; 2. Sabemos que existe um índice especifico para o tipo de dados TEXT no SQL Server, mas não podemos adotar esta solução; 3. Alteramos a query com JOIN, EXISTS, BETWEEN, <=, >= em nenhuma das alterações houve melhora; 4. Já conferimos a configuração Max Degree of Paralelism e está baseado no cálculo processadores/núcleos; 5. A análise dos traces pelo Tuning Advisor simplesmente não geram recomendações; 6. Os objetos não estão com porcentual de fragmentação, a manutenção é executada semanalmente;