Pesquisar na Comunidade
Mostrando resultados para as tags ''pivot''.
Encontrado 4 registros
-
 Um bom dia a todos os colegas do fórum. Tenho as seguintes tabelas: Necessito criar uma consulta que totalize por DATA, CODIGO_FUNCI, CODIGO_OPE e HORA. sendo o campo HORA separado por horários(07:00 as 07:59, 08:00 as 08:59, 09:00 as 09:59, 10:00 as 10:59, e assim por diante. A consulta ficaria mais ou menos assim: Alguém poderia me auxiliar utilizando as funções PIVOT ou CROSS-APPLY juntamente com INNER JOIN? Desde já eu agradeço.
Um bom dia a todos os colegas do fórum. Tenho as seguintes tabelas: Necessito criar uma consulta que totalize por DATA, CODIGO_FUNCI, CODIGO_OPE e HORA. sendo o campo HORA separado por horários(07:00 as 07:59, 08:00 as 08:59, 09:00 as 09:59, 10:00 as 10:59, e assim por diante. A consulta ficaria mais ou menos assim: Alguém poderia me auxiliar utilizando as funções PIVOT ou CROSS-APPLY juntamente com INNER JOIN? Desde já eu agradeço. -
Boa tarde, preciso executar uma consulta de referência cruzada que receba um valor de entrada do usuário, a consulta está assim: TRANSFORM Count(OCORRENCIAS.Culpabilidade) AS Culpabilidade SELECT Month(OCORRENCIAS.[Data]) AS Mes, Count(OCORRENCIAS.Culpabilidade) AS Total FROM OCORRENCIAS WHERE (((Year([OCORRENCIAS].[Data]))= "2018")) GROUP BY Month(OCORRENCIAS.[Data]) PIVOT OCORRENCIAS.Culpabilidade; Está executando sem problemas porém preciso que o filtro do Ano da pesquisa seja fornecido no momento de executar a consulta, quando troco o "2018" por [Inserir ano pesquisa] apresenta mensagem de erro "O mecanismo de banco de dados não reconhece [Inserir ano pesquisa] como um campo ou expressão válida", vi em outras postagem sugerindo para declarar o parâmetro, adicionei PARAMETERS [Inserir ano pesquisa] Short; no inicio do código, porém agora ele apresenta a janela para inserir a variável duas vezes (algumas vezes ele mostra 3 vezes a janela de entrada), alguém sabe como resolver este problema?
-
Olá pessoAll, Tenho a seguinte estrutura montada no SQL Server. O que está apresentado em vermelho eu já consegui adequar para o MySql, porém a montagem do pivot (em verde) e a criação da tabela final de saída (em azul) ainda não consegui converter para a linguagem do MySql. Será que alguém poderia me ajudar nesta conversão? De ante mão agradeço a colaboração de todos. 1 - Esta montagem resulta em 4 tabelas distintas denominadas Tabela_Semana1_CPU, Tabela_Semana2_CPU, Tabela_Semana3_CPU e Tabela_Semana4_CPU. if OBJECT_ID('Tabela_Semana1_CPU', 'U') is not null drop table Tabela_Semana1_CPU; select w.servidor, w.origem, cast(avg(w.cpu_avg) as decimal(10,2)) as Media into Tabela_Semana1_CPU from (Select source as SERVIDOR, origin as origem, cast(sampletime as date) as sampletime, cast(avg(samplevalue) as decimal (10,2)) as cpu_avg from V_QOS_CPU_USAGE WITH (NOLOCK) where target = 'Total' and sampletime between cast(dateadd(day, -27, getdate()) as date) and cast(dateadd(day, -20, getdate()) as date) group by source, origin, cast(sampletime as date)) w group by w.servidor, w.origem if OBJECT_ID('Tabela_Semana2_CPU', 'U') is not null drop table Tabela_Semana2_CPU; select w.servidor, w.origem, cast(avg(w.cpu_avg) as decimal(10,2)) as Media into Tabela_Semana2_CPU from (Select source as SERVIDOR, origin as origem, cast(sampletime as date) as sampletime, cast(avg(samplevalue) as decimal (10,2)) as cpu_avg from V_QOS_CPU_USAGE WITH (NOLOCK) where target = 'Total' and sampletime between cast(dateadd(day, -20, getdate()) as date) and cast(dateadd(day, -13, getdate()) as date) group by source, origin, cast(sampletime as date)) w group by w.servidor, w.origem if OBJECT_ID('Tabela_Semana3_CPU', 'U') is not null drop table Tabela_Semana3_CPU; select w.servidor, w.origem, cast(avg(w.cpu_avg) as decimal(10,2)) as Media into Tabela_Semana3_CPU from (Select source as SERVIDOR, origin as origem, cast(sampletime as date) as sampletime, cast(avg(samplevalue) as decimal (10,2)) as cpu_avg from V_QOS_CPU_USAGE WITH (NOLOCK) where target = 'Total' and sampletime between cast(dateadd(day, -13, getdate()) as date) and cast(dateadd(day, -6, getdate()) as date) group by source, origin, cast(sampletime as date)) w group by w.servidor, w.origem if OBJECT_ID('Tabela_Semana4_CPU', 'U') is not null drop table Tabela_Semana4_CPU; select w.servidor, w.origem, cast(avg(w.cpu_avg) as decimal(10,2)) as Media into Tabela_Semana4_CPU from (Select source as SERVIDOR, origin as origem, cast(sampletime as date) as sampletime, cast(avg(samplevalue) as decimal (10,2)) as cpu_avg from V_QOS_CPU_USAGE WITH (NOLOCK) where target = 'Total' and sampletime between cast(dateadd(day, -6, getdate()) as date) and cast(dateadd(day, 1, getdate()) as date) group by source, origin, cast(sampletime as date)) w group by w.servidor, w.origem Estes são os resultados (este passo já criei no mey MySql o esquivalente): 2 - Em seguida faço um pivot desta tabela que resulta uma uma tabela única denominada TabelaFinal_Semanal_CPU: if OBJECT_ID('TabelaFinal_Semanal_CPU', 'U') is not null drop table TabelaFinal_Semanal_CPU; with TabUnica (Semanas, SERVIDOR, origem, cpu_avg) as ( SELECT '1', SERVIDOR, origem, media from Tabela_Semana1_CPU union all SELECT '2', SERVIDOR, origem, media from Tabela_Semana2_CPU union all SELECT '3', SERVIDOR, origem, media from Tabela_Semana3_CPU union all SELECT '4', SERVIDOR, origem, media from Tabela_Semana4_CPU ) SELECT SERVIDOR, origem, cast([1] as Numeric(10,2)) as 'Semana1', cast([2] as Numeric(10,2)) as 'Semana2', cast([3] as Numeric(10,2)) as 'Semana3', cast([4] as Numeric(10,2)) as 'Semana4' INTO TabelaFinal_Semanal_CPU from TabUnica pivot (Avg(CPU_Avg) for Semanas in ([1], [2], [3], [4])) as P where SERVIDOR not in ('sprod01') order by Servidor; alter table TabelaFinal_Semanal_CPU with NOCHECK add [Previsao_Semana5] as cast(((Semana4 / Semana3) * Semana4) as decimal(10,2)) alter table TabelaFinal_Semanal_CPU with NOCHECK add [Previsao_Semana6] as cast(((((Semana4 / Semana3) * Semana4) / Semana4) * (Semana4 / Semana3) * Semana4) as decimal(10,2)) alter table TabelaFinal_Semanal_CPU with NOCHECK add [Previsao_Semana7] as cast(((((((Semana4 / Semana3) * Semana4) / Semana4) * (Semana4 / Semana3) * Semana4)) / ((Semana4 / Semana3) * Semana4) * ((((Semana4 / Semana3) * Semana4) / Semana4) * (Semana4 / Semana3) * Semana4)) as decimal(10,2)) Estes são os resultados (observem que o alter foi criado para inclusão das três últimas colunas baseadas em alguns cálculos): 3 - E, por fim gero esta última tabela, que é a que realmente me interessa, denominada TabelaFinal_Data_CPU: if OBJECT_ID('TabelaFinal_Data_CPU', 'U') is not null drop table TabelaFinal_Data_CPU; select SERVIDOR, origem, Semana1, dateadd(day, -20, getdate()) as Data1, Semana2, dateadd(day, -13, getdate()) as Data2, Semana3, dateadd(day, -6, getdate()) as Data3, Semana4, dateadd(day, 0, getdate()) as Data4, Previsao_Semana5, dateadd(day, 7, getdate()) as Data5, Previsao_Semana6, dateadd(day, 14, getdate()) as Data6, Previsao_Semana7, dateadd(day, 21, getdate()) as Data7 INTO TabelaFinal_Data_CPU from TabelaFinal_Semanal_CPU Este é o resultado final (as duas últimas colunas ficaram ocultas devido ao tamanho):
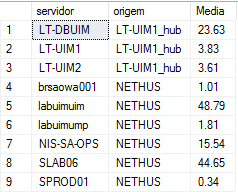
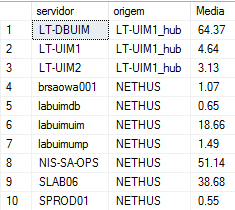
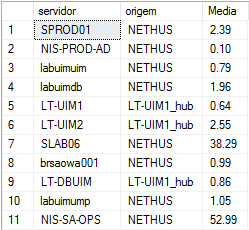

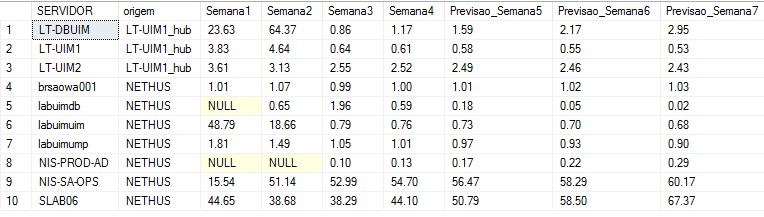

-
Boa noite. Sou inexperiente em bd, mas estou me esforçando. Mas depois de dois dias não consegui resolver e estou necessitando de ajuda. Li bastante sobre PIVOT, mais tentei fazer nos 3 campos que preciso para uma tabela view e não deu certo. Sei que é bastante básico minha dúvida, mas não consigo. Tenho uma tabela de cadastro no ambulatório dentre os campos tenho id, nome, re, cid1, cid2, cid3 Deveria ter feito uma de cid e fazer relacionamento entre cadastro e quais cid's para este funcionário, mas fiz somente uma e agora estou com problemas para saber quais os cid's mais rescindentes dentro do mês somando entre cada cid. Tentei algo do tipo: select cid1, cid2, cid3, count(cid1) + count(cid2) + count(cid3) as total from atestado group by cid1 Até faz, porém multiplica os valores. Alguém poderia me ajudar como fazer ? Obrigado.



