Ronivaldo Lopes
-
Total de itens
39 -
Registro em
-
Última visita
Tudo que Ronivaldo Lopes postou
-

BULK INSERT - BCP - SQL SERVER
pergunta respondeu ao morpheus_ de Ronivaldo Lopes em Tutoriais & Dicas - SQL Server
Boa tarde, o padrão do bulk é utilizar delimitadores de campos e de linhas, como seu arquivo de importação possui tamanho fixo, você precisa fornecer o formato dos campos através do parâmetro FORMATFILE. -
Boa tarde, você esqueceu de colocar o % no final da condição [Entry Type] Like '0%', eu uso a função convert() para trabalhar com datas, e o 112 para o formato yyyymmdd, no lugar do OR uso conjunto. SELECT * FROM [minha base de dados].[minha tabela] WHERE convert(char(8), [Posting Date], 112) BETWEEN '20210101' AND '20221231' AND substring([Item No_],1,2) in ('MI', 'MP', 'PA', 'PC', 'PR', 'PE') AND substring([Entry Type],1,1) = '0'
-
Criar um índice a partir do resultado da query
pergunta respondeu ao Wesley Ribeiro de Ronivaldo Lopes em PostgreSQL
Bom dia, você pode usar WITH Queries (Common Table Expressions), no exemplo, estou chamando o resultado da primeira query de consultaOriginal, e logo após o fechamento do parênteses faço uma nova query utilizando essa consulta como se fosse uma tabela, e as funções DIV e MOD para incrementar o índice e zerar/ incrementar a hora with consultaOriginal as ( select ... from ... group by ... ) select ..., mod((sum_duration + duration_hour), weekly_hour_avaliable) as duration_hour, div((sum_duration + duration_hour), weekly_hour_avaliable) as indice from consultaOriginal -
Boa noite, qual o parâmetro na string de conexão ou outra forma para fazer a função inet_client_addr() retornar o IP cliente ?
-
Melhora na performance de select em tabelas grandes
pergunta respondeu ao Bregnoles de Ronivaldo Lopes em PostgreSQL
Boa noite, por padrão essas opções já estão on e se mudar para off, você diminuirá as opções para que o PostgreSQL tente selecionar o melhor plano de execução das consultas e isso não vai resolver o problema de performance. Verifique a modelagem do seu banco, provavelmente é onde está seu problema, e principalmente, arquivos de índices não se restringem a chaves primarias e estrangeiras. Há alguns anos fui na empresa de distribuição de energia elétrica, e o sistema de faturamento levava horas processando para começar a imprimir os relatórios. As tabelas não possuíam os índices necessários para emissão dos relatórios, na época usavam o firebird, criei tais índices e a impressão passou a ser instantânea. -
Concatenar hora e não trazer os segundos junto.
pergunta respondeu ao Vinicius kowalski de Ronivaldo Lopes em PostgreSQL
boa tarde, transforme em caractere usando ::char(5), caso o campo for do tipo time, pode fazer a conversão direta, sem usar ::time concat(e.hora_inicial::time::char(5), '-', e.hora_final::time::char(5)) concat(e.hora_inicial::char(5), '-', e.hora_final::char(5)) e.hora_inicial::char(5) || '-' || e.hora_final::char(5)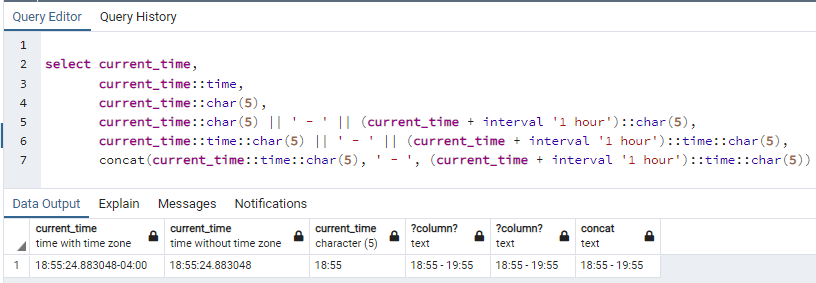
-
Select que não usam PK ou Index das tabelas pequenas
pergunta respondeu ao Bregnoles de Ronivaldo Lopes em PostgreSQL
Boa noite, existem vários ram disk no mercado, eu uso o ImDisk que é free, configuro a pasta ?:/temp para as variáveis temp e tmp do windows e pasta temporária do postgresql. Uso também para download. No linux pode criar via linha de comando myramdisk /tmp/ramdisk tmpfs defaults,size=4G,x-gvfs-show 0 0 https://sourceforge.net/projects/imdisk-toolkit/ Você instala e configura só a primeira aba, só mude o tamanho da ram que será utilizada, a letra e definir as variáveis temp, toda vez que a maquina for reiniciada ou ligada, essa unidade de disco virtual será criada (figura abaixo). O seu comando CREATE DATABASE está criando todo o banco na pasta F:/tmp_tablespace, tabelas temporárias ou não. Embora você tenha especificado a pasta padrão (tablespace) onde seu banco dbspace_tmp será gravado, você pode especificar um tablespace diferente no comando create table, ou seja, pode usar mais de uma pasta, em discos diferentes para o mesmo banco. create temp table teste tablespace xxx as select s::int as id, ('Nome ' || to_char(s, 'FM0000'))::varchar(15) as nome from generate_series(1,1000) x(s); Nos comandos abaixo, o postgresql vinculará a pasta d:/temp ao tablespace temp_pg, que criará outra pasta cujo nome inicia com PG_ dentro da pasta d:/temp, no disco virtual. Quando você executa o comando create table, e se verificar dentro da pasta criada, haverá um único arquivo que é a tabela teste, quando você executa o comando create index, aparecerá o segundo arquivo que é o arquivo de índice dentro da mesma pasta, já que a tabela é temporária, o índice também será temporário. Quando executar o drop table teste, os dois arquivos serão excluídos. CREATE TABLESPACE temp_pg LOCATION 'd:/temp'; set temp_tablespaces = temp_pg; drop table if exists teste; create temp table teste as select s::int as id, ('Nome ' || to_char(s, 'FM0000000'))::varchar(15) as nome from generate_series(1,1000000) x(s); create index teste1 on teste (id); drop table teste; Sempre trabalhei com SQL Server, ainda estou estudando o postgresql e não sei muito sobre configuração. Mas um bom SSD, memória ram e o uso de um disco virtual faz a diferença. Tenho um sistema no SQL Server, esse servidor utiliza disco rígido e demora uns 3 minutos para executar uma determinada rotina, no postgreql essa mesma rotina executa em 6 segundos utilizando SSD, o meu SSD é de 2,5gb/s e se fosse de 7gb/s seria em um piscar de olhos.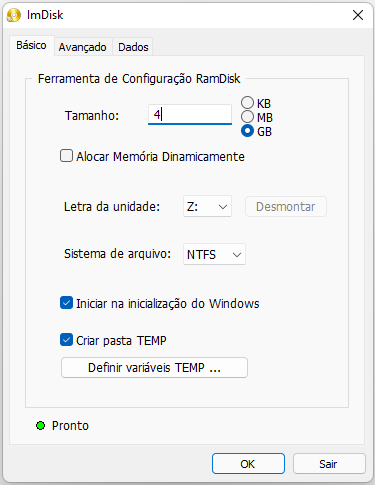
-
Select que não usam PK ou Index das tabelas pequenas
pergunta respondeu ao Bregnoles de Ronivaldo Lopes em PostgreSQL
Boa tarde, por padrão essas opções são on, e como o coletor de estatísticas registra as atividades no banco de dados, o postgresql usa essas estatísticas para definir a melhor execução dos comandos, isso é dinâmico, quando os comandos são executados, as novas estatísticas são feitas. Eu deixo o padrão, mudo para fazer os testes de performance. Gosto de fazer toda programação dentro do banco e faço uso intensivo de tabelas temporárias. Outra técnica para melhorar a performance, é utilizar parte da memória ram para criar um disco virtual, configurar tablespace temp_pg para uma pasta nesse disco, e usar o temp_pg para criar todas as tabelas e índices temporários, além de poupar a unidade de disco SSD, possui um acesso mais rápido. -
Select que não usam PK ou Index das tabelas pequenas
pergunta respondeu ao Bregnoles de Ronivaldo Lopes em PostgreSQL
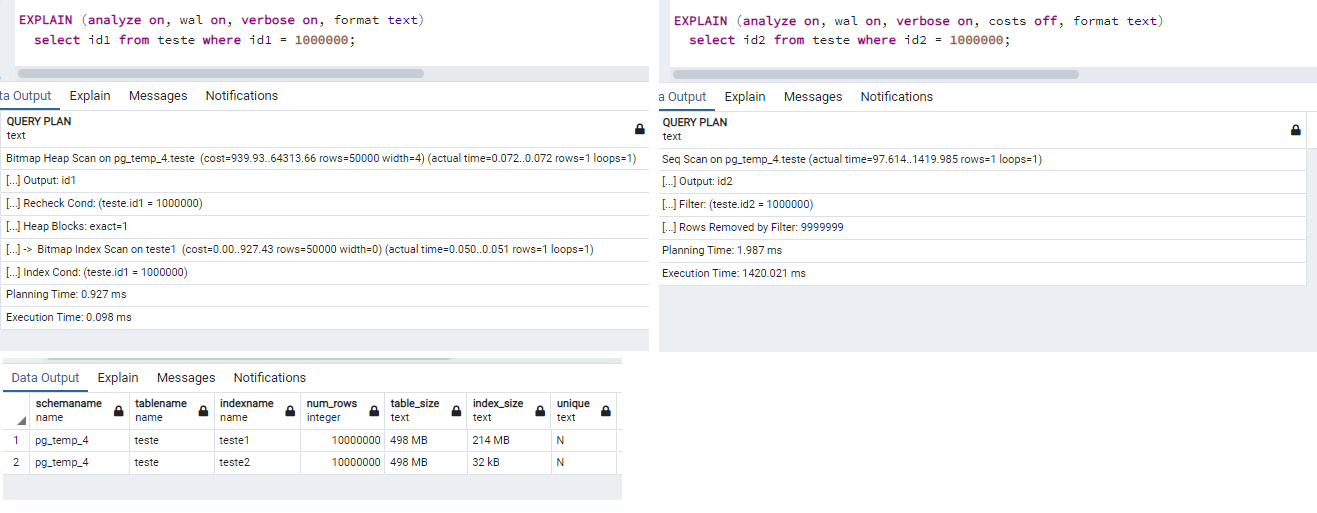
Boa noite, Respondendo a primeira pergunta, o uso ou não de índices não está relacionado somente com a quantidade de registros. Para que o POSTGRESQL possa selecionar o melhor plano de execução das consultas, é necessário que as tabelas tenham dados estatísticos. No exemplo abaixo criei uma tabela com 10 milhões de registros e 2 arquivos de índices. O primeiro índice do tipo B-TREE ocupou 214 MB e o segundo do tipo BRIN ocupou somente 32 KB, este segundo índice é usado para BIG DATA. Executando a primeira consulta do campo id1, o índice teste1 foi utilizado automaticamente, já na segunda consulta utilizando o campo id2, o índice teste2 não foi utilizado, sendo sequencial. Somente após a execução do comando ANALIZE para gerar os dados estatísticos da tabela e uma nova execução, o segundo índice foi utilizado. create temp table teste as select s::int as id1, s::int as id2, quote_ident('Nome ' || to_char(s, 'FM00000000'))::varchar(15) as nome from generate_series(1,10000000) x(s); create index teste1 on teste (id1); create index teste2 on teste using brin (id2); EXPLAIN (analyze on, wal on, verbose on, costs off, format text) select id1 from teste where id1 = 1000000; EXPLAIN (analyze on, wal on, verbose on, costs off, format text) select id2 from teste where id2 = 1000000; Analyze VERBOSE teste;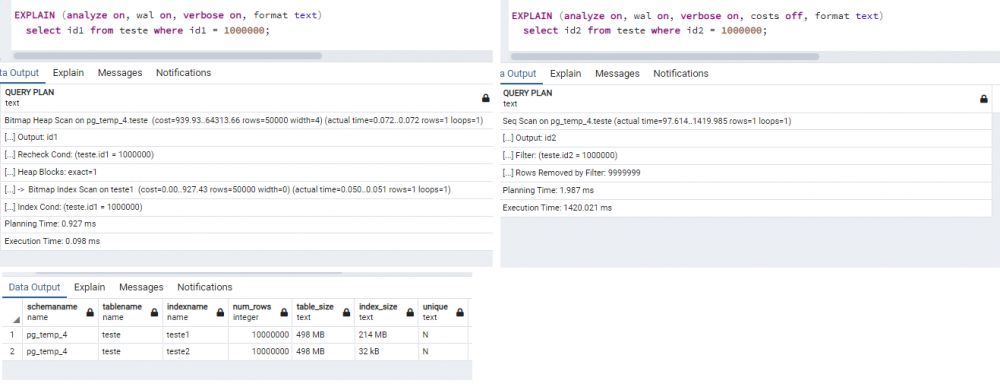
-
Select que não usam PK ou Index das tabelas pequenas
pergunta respondeu ao Bregnoles de Ronivaldo Lopes em PostgreSQL
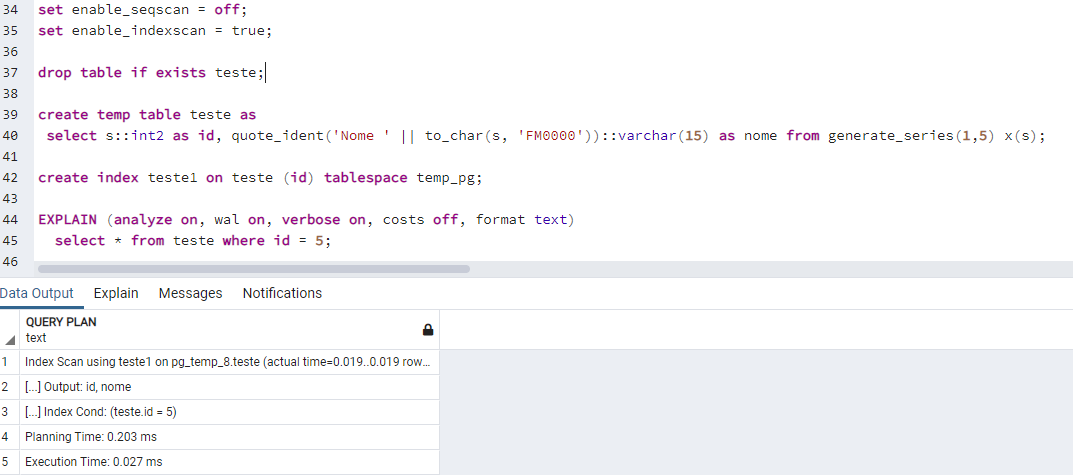
Boa noite, execute os comandos abaixo para desabilitar a busca sequencial e forçar o uso de índices. O SELECT em tabelas com poucos registros será utilizado o índice, caso exista. set enable_seqscan = off; set enable_indexscan = true;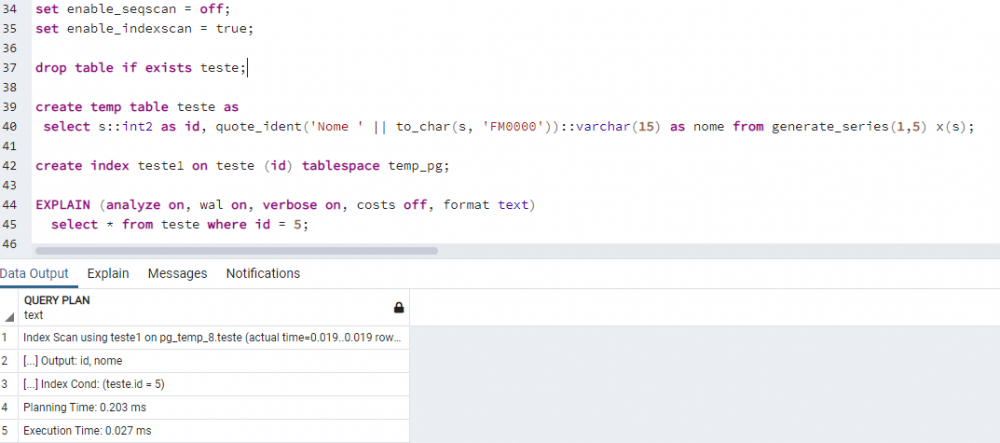
-
No comando Select você deve utilizar a função quote_ident ( ) nos campos desejados copy (selet id, quote_ident ( banco_nm ) from bancos) .....
-
Bom dia, você pode salvar a planilha no formato TXT, definindo um delimitador de campo e o conteúdo para campos nulos. No exemplo abaixo, utilizo o comando COPY para incluir o conteúdo do arquivo BANCOS.TXT na tabela BANCOS que possui 3 campos ( id, banco_nm, disponivel ), utilizo o caractere '|' como delimitador e para os campos nulo preencho com o conteúdo '*null*'. Copy bancos ( id, banco_nm, disponivel ) From 'z:/bancos.txt' With Delimiter '|' NULL '*null*'; O arquivo banco.txt deve ficar assim 001|BANCO DO BRASIL SA|True 003|BANCO DA AMAZONIA S/A|True 104|CAIXA ECONÔMICA FEDERAL|True 237|BANCO BRADESCO S/A|*null*
-
Criar uma View utilizando IF Else como condição
pergunta respondeu ao Ivan.Santos.2509 de Ronivaldo Lopes em SQL Server
create view teste as Select NmFuncionario from tfuncionarios Where iif(patindex('%SANTOS%', NmFuncionario) > 0, 1, 0) = iif(day(Getdate()) = 12, 1, 0) -
Alguma Hospedagem Online gratuita para utilizar em conjunto com o Lazarus ou C++?
pergunta respondeu ao Efraim Micaías de Ronivaldo Lopes em PostgreSQL
Bom dia, no link tem vários planos, o de até 20mb de dados é free e é só configurar a string de conexão no lazarus. Uso sem problemas. www.elephantsql.com