Pesquisar na Comunidade
Mostrando resultados para as tags ''crawler''.
Encontrado 3 registros
-
Olá rapaziada tudo certo? Estou basicamente criando listas referentes aos endereços de grandes franquias como a Dominos Pizza por exemplo: para tal feito, usei do seguinte codigo: <?php $file = file_get_contents("https://pastebin.com/raw/PGz2iNtQ"); $json = json_decode($file); for ($i=0; $i < 200; $i++) { echo $json->Stores[$i]->LocationInfo."<br><br>"; } ?> Este exemplo de codigo lista todos os endereços que foram encontrados no site da pizzaria, por meio de um arquivo JSON. O resultado da lista é o seguinte: https://pastebin.com/eVC50N1M Porem, necessito das informaçoes do BOBS, so que dessa vez, não achei nada em JSON no site, o referente aos endereços do mesmo é o seguinte: pdv.mapa.js Peço encarecidamente que alguém que manje do assunto me de uma luz de como fazer algo semelhante ao que eu fiz na 'Dominos' com o 'Bobs'.
-
Seguinte, pessoal. O portal de notas da minha faculdade se apresenta conforme a imagem em anexo. Vejam que cada matéria possui 3 provas. Alguns professores cadastram as 3 de uma vez, e fica pendente só o valor da nota no final. Outros nem cadastram as provas. Eu precisava de um robô que varresse essa página e informasse toda vez que algum professor cadastrar uma nova nota. Tem como fazer isso?
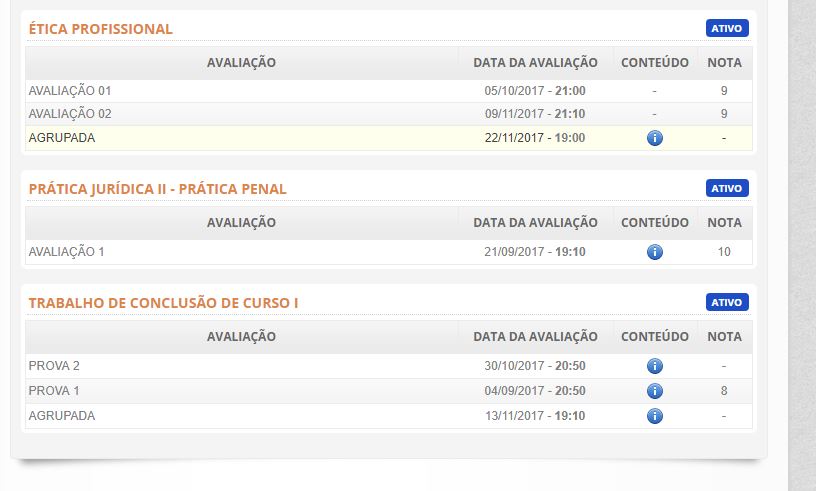
-
 Fala pessoal. Faz um tempo que estou baixando animes de um site, porem ele é mt pesado e da um pouco de preguiça de ver quais ja foram traduzidos e postados no site. E faz um tempo tambem que quero fazer um programa que pegue os links de download ou algo do tipo. Quando pensei em faze-lo, a primeira coisa que me veio à cabeça foi Visual Basic. Eu não estou na faculdade ainda, porem é algo que eu curto muito desde o meu primeiro curso de informatica, onde estudei HTML. Desde então venho querendo e adquirindo conhecimento sobre a area de ciencias da computação. Eu dei umas pesquisadas e tenho certa base e um norte. Olhei o codigo-fonte do site em questão e percebi que não teria como fazer por biblioteca. Porem, os links e tags estavam dentro de <div> </div> <div class="links_720p"> <div class="links_whole"> <div class="botao-download" style="display: inline-block;float: none;" data-urltratada="LINK DE DOWNLOAD" data-index="1"><a href="exemplo_com" target="_blank"> <span class="btn-download-words">FILE4GO</span> <img src="exemplo" class="btn-minilogo"> </a></div> <div class="botao-download" style="display: inline-block;float: none;" LINK DE DOWNLOAD 2" data-index="2"><a href="exemplo_com" target="_blank"> <span class="btn-download-words">DRIVE</span> <img src="exemplo_com" class="btn-minilogo"> </a></div> <div class="botao-download" style="display: inline-block;float: none;" data-urltratada="LINK 2"><a href="exemplo_com" target="_blank"> <span class="btn-download-words">MEGA</span> <img src="exemplo_com" class="btn-minilogo"> </a></div> <div class="botao-download" style="display: inline-block;float: none;" data-urltratada="https://openload.co/f/oMNVRwVSNqM/%5BAnimes_Telecine%5D_Gin_no_Guardian_-_01_%5B720p%5D.mkv<br" data-index="4"><a href="exemplo_com" target="_blank"> <span class="btn-download-words">OPENLOAD</span> <img src=exemplo_com" class="btn-minilogo"> </a></div> Perguntas: 1. Tem como pegar somente o que fica dentro dessa tag ou algo assim? 1,2. Se sim como? 2.Se não tiver como, alguem pode me dar uma dica de outro CAMINHO para seguir? Obs: Não quero scripts prontos, eu gostaria de uma leve explicação e/ou dica de que caminho seguir, pois apenas estou iniciando nesta area. ^^ Obs.2: Os motivos de eu querer criar algo assim é totalmente para treino e para facilitar minha vida. Não pretendo lucrar com isso, até pq deve ser simples o fazer.
Fala pessoal. Faz um tempo que estou baixando animes de um site, porem ele é mt pesado e da um pouco de preguiça de ver quais ja foram traduzidos e postados no site. E faz um tempo tambem que quero fazer um programa que pegue os links de download ou algo do tipo. Quando pensei em faze-lo, a primeira coisa que me veio à cabeça foi Visual Basic. Eu não estou na faculdade ainda, porem é algo que eu curto muito desde o meu primeiro curso de informatica, onde estudei HTML. Desde então venho querendo e adquirindo conhecimento sobre a area de ciencias da computação. Eu dei umas pesquisadas e tenho certa base e um norte. Olhei o codigo-fonte do site em questão e percebi que não teria como fazer por biblioteca. Porem, os links e tags estavam dentro de <div> </div> <div class="links_720p"> <div class="links_whole"> <div class="botao-download" style="display: inline-block;float: none;" data-urltratada="LINK DE DOWNLOAD" data-index="1"><a href="exemplo_com" target="_blank"> <span class="btn-download-words">FILE4GO</span> <img src="exemplo" class="btn-minilogo"> </a></div> <div class="botao-download" style="display: inline-block;float: none;" LINK DE DOWNLOAD 2" data-index="2"><a href="exemplo_com" target="_blank"> <span class="btn-download-words">DRIVE</span> <img src="exemplo_com" class="btn-minilogo"> </a></div> <div class="botao-download" style="display: inline-block;float: none;" data-urltratada="LINK 2"><a href="exemplo_com" target="_blank"> <span class="btn-download-words">MEGA</span> <img src="exemplo_com" class="btn-minilogo"> </a></div> <div class="botao-download" style="display: inline-block;float: none;" data-urltratada="https://openload.co/f/oMNVRwVSNqM/%5BAnimes_Telecine%5D_Gin_no_Guardian_-_01_%5B720p%5D.mkv<br" data-index="4"><a href="exemplo_com" target="_blank"> <span class="btn-download-words">OPENLOAD</span> <img src=exemplo_com" class="btn-minilogo"> </a></div> Perguntas: 1. Tem como pegar somente o que fica dentro dessa tag ou algo assim? 1,2. Se sim como? 2.Se não tiver como, alguem pode me dar uma dica de outro CAMINHO para seguir? Obs: Não quero scripts prontos, eu gostaria de uma leve explicação e/ou dica de que caminho seguir, pois apenas estou iniciando nesta area. ^^ Obs.2: Os motivos de eu querer criar algo assim é totalmente para treino e para facilitar minha vida. Não pretendo lucrar com isso, até pq deve ser simples o fazer.

