Ronivaldo Lopes
-
Total de itens
39 -
Registro em
-
Última visita
Tudo que Ronivaldo Lopes postou
-

Monitorar atividades dos usuários - Postgres
pergunta respondeu ao Ninja2112 de Ronivaldo Lopes em PostgreSQL
Bom dia, uso uma única trigger genérica e uma única tabela para gravar o log de todas as tabelas a serem monitoradas. Todos os campos das tabelas são gravados no campo dados1 do tipo jsonb. No exemplo1, todas as tabelas tem como chave o campo id, e para comandos update, somente os campos que foram atualizados são gravados nos campos dados1 e dados2, depois e antes da atualização, respectivamente. Você pode simplificar e fazer o comando do insert funcionar para o update (exemplo2), nesse caso pode excluir o campo dados2 da tabela _generic_log. Caso deseje gravar os dados antes da alteração, e as tabela possuírem os campos chaves com nomes diferentes, já que se trata de um banco antigo, para cada tabela repetir o comando, substituindo a palavra key pelo nome da campo chave da tabela (exemplo3). Na ultima parte, tem a rotina que associa todas as tabelas do banco para gravar na tabela _generic_log, com exceção as tabelas que estão as linha do IF, nesse caso a própria tabela _generic_log, pois entrará em loop ao incluir seu próprio log. Feito isso, a tabela _generic_log terá as informações necessárias para você monitorar todas as ações dos usuários. -- ******************** drop table if exists public._generic_log; create table public._generic_log ( id serial not null primary key, tabela varchar(50) not null, usuario varchar(50) not null default current_setting('app.user_name'), ip_address varchar(15) not null default current_setting('app.ip_address'), mac_address varchar(17) not null default current_setting('app.mac_address'), data_hora int8 not null default to_char(now(), 'yyyymmddHH24missms')::int8, operacao char not null check (operacao in ('I', 'U', 'D')), dados1 jsonb not null, dados2 jsonb null ); create index _generic_log_ind on public._generic_log using brin ( tabela ); -- *************************************************** exemplo1 drop function if exists public.check_generic_log(); create or replace function public.check_generic_log() returns trigger as $$ begin if tg_op = 'INSERT' then insert into _generic_log ( tabela, operacao, dados1 ) select tg_table_name, tg_op::char, jsonb_object_agg( n.key, n.value ) from jsonb_each( to_jsonb( new ) ) n; elseif tg_op = 'DELETE' then insert into _generic_log ( tabela, operacao, dados1 ) select tg_table_name, tg_op::char, jsonb_object_agg( o.key, o.value ) from jsonb_each( to_jsonb( old ) ) o; else -- update insert into _generic_log (tabela, operacao, dados1, dados2 ) select * from ( select tg_table_name, tg_op::char, jsonb_object_agg( n.key, n.value ) as dados1, jsonb_object_agg( o.key, o.value ) as dados2 from jsonb_each( to_jsonb( new ) ) n join jsonb_each( to_jsonb( old ) ) o on n.key = o.key where n.key in ('id','n.key') or (coalesce(n.value, o.value) is distinct from coalesce(o.value, n.value) and n.key <> 'data_hora_log')) a where dados1 <> dados2; end if; return null; end; $$ language plpgsql;] -- **************************** exemplo2 drop function if exists public.check_generic_log(); create or replace function public.check_generic_log() returns trigger as $$ begin if (tg_op = 'INSERT') or (tg_op = 'UPDATE') then insert into _generic_log ( tabela, operacao, dados1 ) select tg_table_name, tg_op::char, jsonb_object_agg( n.key, n.value ) from jsonb_each( to_jsonb( new ) ) n; elseif tg_op = 'DELETE' then insert into _generic_log ( tabela, operacao, dados1 ) select tg_table_name, tg_op::char, jsonb_object_agg( o.key, o.value ) from jsonb_each( to_jsonb( old ) ) o; end if; return null; end; $$ language plpgsql; -- **************************** exemplo3 drop function if exists public.check_generic_log(); create or replace function public.check_generic_log() returns trigger as $$ begin if (tg_op = 'INSERT') or (tg_op = 'UPDATE') then insert into _generic_log ( tabela, operacao, dados1 ) select tg_table_name, tg_op::char, jsonb_object_agg( n.key, n.value ) from jsonb_each( to_jsonb( new ) ) n; elseif tg_op = 'DELETE' then insert into _generic_log ( tabela, operacao, dados1 ) select tg_table_name, tg_op::char, jsonb_object_agg( o.key, o.value ) from jsonb_each( to_jsonb( old ) ) o; else -- update if tg_table_name = 'bancos' then insert into _generic_log (tabela, operacao, dados1, dados2 ) select * from ( select tg_table_name, tg_op::char, jsonb_object_agg( n.key, n.value ) as dados1, jsonb_object_agg( o.key, o.value ) as dados2 from jsonb_each( to_jsonb( new ) ) n join jsonb_each( to_jsonb( old ) ) o on n.cdbanco = o.cdbanco where n.key in ('cdbanco','n.key') or (coalesce(n.value, o.value) is distinct from coalesce(o.value, n.value) and n.key <> 'data_hora_log')) a where dados1 <> dados2; elseif tg_table_name = 'agencias' then insert into _generic_log (tabela, operacao, dados1, dados2 ) select * from ( select tg_table_name, tg_op::char, jsonb_object_agg( n.key, n.value ) as dados1, jsonb_object_agg( o.key, o.value ) as dados2 from jsonb_each( to_jsonb( new ) ) n join jsonb_each( to_jsonb( old ) ) o on n.cdagencia = o.cdagencia where n.key in ('cdagencia','n.key') or (coalesce(n.value, o.value) is distinct from coalesce(o.value, n.value) and n.key <> 'data_hora_log')) a where dados1 <> dados2; end if; end if; return null; end; $$ language plpgsql; -- *************************************************** -- *************************************************** -- -- Executa a trigger generica para todas as tabela do banco de dados -- do $$ declare _tabela varchar(100); declare _obj record; begin for _obj in select schemaname as schema, relname as tabela from pg_stat_user_tables where substring(relname for 1 from 1) <> '_' order by relname loop _tabela := _obj.schema || '.' || _obj.tabela; execute format('drop trigger if exists log_generic on %s;', _tabela ); execute format('drop trigger if exists log_generic_update on %s;', _tabela ); if not _obj.tabela = any (values ('_generic_log','_tabela1...','_tabela2...')) then -- insert or delete execute format('create trigger log_generic after insert or delete on %s for each row execute function public.check_generic_log();', _tabela ); -- update --> somente se houve alteração ==> for each row WHEN (old.* is distinct from new.*) execute format('create trigger log_generic_update after update on %s for each row when (old.* is distinct from new.*) execute function public.check_generic_log();', _tabela ); end if; end loop; end; $$ -
Como criar uma cópia da tabela com a data atual no nome no Postgres?
pergunta respondeu ao Antonio Massei de Ronivaldo Lopes em PostgreSQL
Bom dia, na clausula including você pode especificar o que copiar (defaults, constraints, indexes, all), o que não acontece com o "create table tab_a as select * from tab_b". do $$ begin execute 'create table tbl_01_' || to_char(now(), 'yyyymmddHH24missms') || ' (like tbl_01 including all)'; end; $$ ou do $$ begin execute format('create table tbl_01_%s (like tbl_01 including all)', to_char(now(), 'yyyymmddHH24missms')); end; $$ -
sqlserver Como Unir Duas Tabelas com Distribuição Exata de Dados no SQL Server?
pergunta respondeu ao TavinhoBRMG de Ronivaldo Lopes em SQL Server
Bom dia, na tabela de Cad_Clients, cada cliente possui 1 Ctrl, na tabela de Cad_Colors, o Ctrl pode ter mais uma cor, resumindo a cliente pode ter mais de uma cor. select a.*, b.Color from Cad_Clients a left join Cad_Colors b on a.Ctrl = b.Ctrl where b.Ctrl is not null order by a.idPerson 100 -> Red 103 -> Yellow 104 -> Blue e Purple 105 -> Green e Red resultado da query idperson person ctrl color 1 John 100 Red 4 Emily 103 Yellow 5 William 104 Blue 5 William 104 Purple 6 Olivia 105 Red 6 Olivia 105 Green 7 James 100 Red 10 Sophia 103 Yellow 11 Samuel 104 Purple 11 Samuel 104 Blue 12 Ava 105 Red 12 Ava 105 Green 13 Joseph 100 Red -
Boa tarde, quando eu trabalhava com SQL Server, eu usava a função Convert, o ultimo parâmetro, nesse caso o 111, é o formato yyyy/mm/dd, sendo que existem outros formatos. Qtde de registros por data select Convert(Char(10), data, 111) as data, sum(1) as qtde from tabela group by Convert(Char(10), data, 111) order by Convert(Char(10), data, 111) Somente datas select distinct Convert(Char(10), data, 111) from tabela Não tenho o SQL Server pata testar
-
Erro ao importar campo valor de arquivo txt
pergunta respondeu ao José Aparecido Pimentel de Ronivaldo Lopes em SQL Server
Faça o teste sem a primeira e a ultima barra, você pode utilizar o excel para abrir a ser importado, exclua as colunas em branco antes da primeira barra e depois da ultima barra, e gere novamente o arquivo sem essas duas barras. -
Erro ao importar campo valor de arquivo txt
pergunta respondeu ao José Aparecido Pimentel de Ronivaldo Lopes em SQL Server
Bom dia, não tenho o SQL Server instalado para testar, mas a primeira e a ultima barra não devem existir no arquivo a ser importado, a barra está sendo utilizada como delimitador dos campos, ou seja, use somente entre os campos. Utilize o assistente de exportação e gere um arquivo para verificar como fica o resultado. -
Function retornando resultado em formato JSON
pergunta respondeu ao ljsantos de Ronivaldo Lopes em PostgreSQL
Acontece, já fiz isso também. 👍 -
Function retornando resultado em formato JSON
pergunta respondeu ao ljsantos de Ronivaldo Lopes em PostgreSQL
Bom dia, você tem que executar com 'select * from funcao()' e não com 'select funcao()'. Sua função retorna uma tabela, você pode selecionar somente os campos necessários e não todos os campos ( * ). SELECT * from relacional.lista_pedido_site_status_data('Gold', NULL,NULL,NULL); -
Consulta ou Função para montar linha do tempo
pergunta respondeu ao Gildecy Júnior Lisboa Calabró de Ronivaldo Lopes em PostgreSQL
. -
Cláusula Where - Deve retornar lista selecionada (In) e ou se em branco Tudo
pergunta respondeu ao Treinamento BHP de Ronivaldo Lopes em SQL Server
Bom dia, há alguns anos deixei de usar o SQL Server e não tenho como testar. O operador "IN" é utilizado para verificar uma lista de expressões, e o erro pode ser que o parâmetro seja uma STRING, se for o caso, você pode utilizar a condição abaixo. where case when trim(@parametro) = '' then true else charindex(uf, @parametro) > 0 end -
Consulta ou Função para montar linha do tempo
pergunta respondeu ao Gildecy Júnior Lisboa Calabró de Ronivaldo Lopes em PostgreSQL
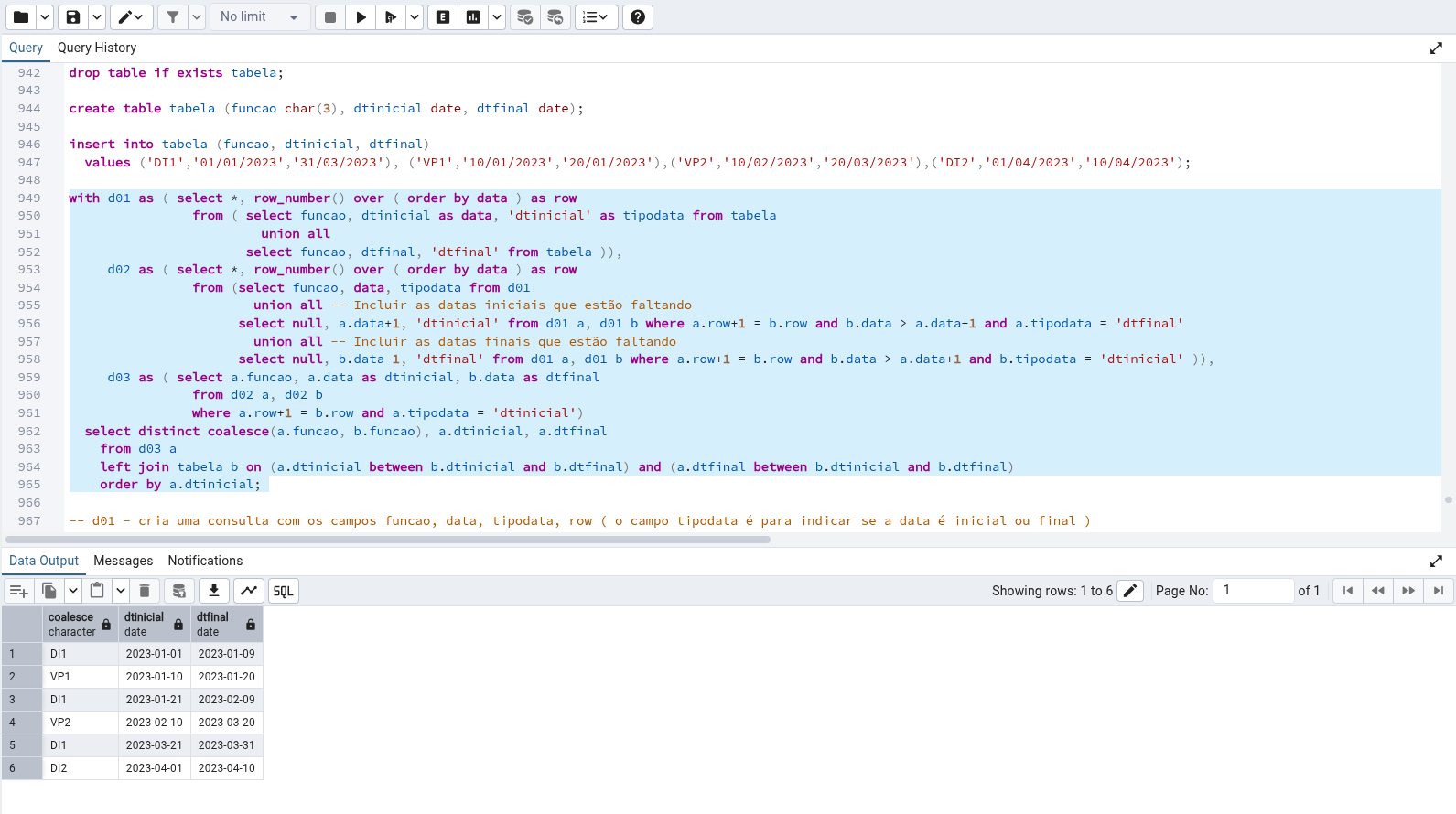
Boa noite, segue uma solução. -- Criar a tabela e incluir os registros drop table if exists tabela; create table tabela (funcao char(3), dtinicial date, dtfinal date); insert into tabela (funcao, dtinicial, dtfinal) values ('DI1','01/01/2023','31/03/2023'), ('VP1','10/01/2023','20/01/2023'),('VP2','10/02/2023','20/03/2023'),('DI2','01/04/2023','10/04/2023'); with d01 as ( select *, row_number() over ( order by data ) as row from ( select funcao, dtinicial as data, 'dtinicial' as tipodata from tabela union all select funcao, dtfinal, 'dtfinal' from tabela )), d02 as ( select *, row_number() over ( order by data ) as row from (select funcao, data, tipodata from d01 union all -- Incluir as datas iniciais que estão faltando select null, a.data+1, 'dtinicial' from d01 a, d01 b where a.row+1 = b.row and b.data > a.data+1 and a.tipodata = 'dtfinal' union all -- Incluir as datas finais que estão faltando select null, b.data-1, 'dtfinal' from d01 a, d01 b where a.row+1 = b.row and b.data > a.data+1 and b.tipodata = 'dtinicial' )), d03 as ( select a.funcao, a.data as dtinicial, b.data as dtfinal from d02 a, d02 b where a.row+1 = b.row and a.tipodata = 'dtinicial') select distinct coalesce(a.funcao, b.funcao), a.dtinicial, a.dtfinal from d03 a left join tabela b on (a.dtinicial between b.dtinicial and b.dtfinal) and (a.dtfinal between b.dtinicial and b.dtfinal) order by a.dtinicial; -- d01 - cria uma consulta com os campos funcao, data, tipodata, row ( o campo tipodata é para indicar se a data é inicial ou final ) -- d02 - cria uma consulta e inclui as datas iniciais e data finais que estão faltando -- d03 - cria uma consulta associando as datas inciais com suas repectivas datas finais -- Ultima consulta, incluir as funções que ficaram nulas na consulta d03 select * from tabela; -- Dados originais "DI1" "2023-01-01" "2023-03-31" "VP1" "2023-01-10" "2023-01-20" "VP2" "2023-02-10" "2023-03-20" "DI2" "2023-04-01" "2023-04-10" D01 funcao data tipodata row "DI1" "2023-01-01" "dtinicial" 1 "VP1" "2023-01-10" "dtinicial" 2 "VP1" "2023-01-20" "dtfinal" 3 "VP2" "2023-02-10" "dtinicial" 4 "VP2" "2023-03-20" "dtfinal" 5 "DI1" "2023-03-31" "dtfinal" 6 "DI2" "2023-04-01" "dtinicial" 7 "DI2" "2023-04-10" "dtfinal" 8 D02 funcao data tipodata row "DI1" "2023-01-01" "dtinicial" 1 "2023-01-09" "dtfinal" 2 "VP1" "2023-01-10" "dtinicial" 3 "VP1" "2023-01-20" "dtfinal" 4 "2023-01-21" "dtinicial" 5 "2023-02-09" "dtfinal" 6 "VP2" "2023-02-10" "dtinicial" 7 "VP2" "2023-03-20" "dtfinal" 8 "2023-03-21" "dtinicial" 9 "DI1" "2023-03-31" "dtfinal" 10 "DI2" "2023-04-01" "dtinicial" 11 "DI2" "2023-04-10" "dtfinal" 12 D03 funcao datainicial datafinal "DI1" "2023-01-01" "2023-01-09" "VP1" "2023-01-10" "2023-01-20" "2023-01-21" "2023-02-09" "VP2" "2023-02-10" "2023-03-20" "2023-03-21" "2023-03-31" "DI2" "2023-04-01" "2023-04-10" Resultado Final funcao datainicial datafinal "DI1" "2023-01-01" "2023-01-09" "VP1" "2023-01-10" "2023-01-20" "DI1" "2023-01-21" "2023-02-09" "VP2" "2023-02-10" "2023-03-20" "DI1" "2023-03-21" "2023-03-31" "DI2" "2023-04-01" "2023-04-10"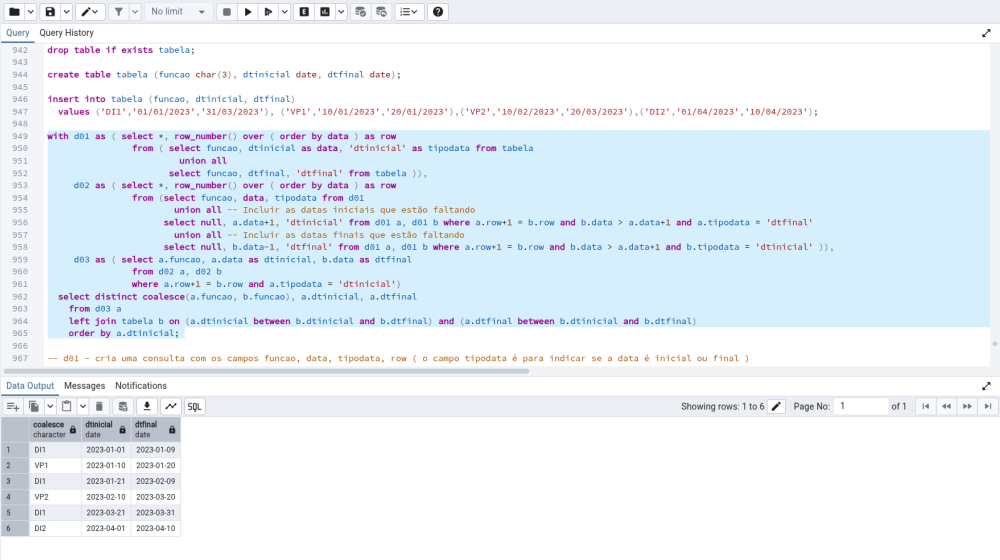
-
Pode usar window functions select * from tabela where id_t in ( select first_value(id_t) over (partition by id_setor, dt_ent) from tabela );
-
Boa tarde, considerando que o campo id_t seja o id da tabela e que seja sequencial e deternine a ordem que os registros são incluídos. No select da clausula where você filtra o período select * from tabela where id_t in (select min(id_t) from tabela where dt_ent between :dtInicial and :dt_final group by id_setor, dt_ent)
-
Boa noite, uso uma trigger genérica para gravar o log de todas as tabelas, uso o tipo de dados jsonb para gravar os campos, e para o arquivo de índice, uso o índice do tipo brin que ocupa pouco espaço no disco, principalmente para tabelas com muitos registros. Todas as tabelas tem com chave o campo id, e para comandos update, são gravados somente são os campos que foram atualizados, antes e depois de atualizados, nos campos dados1 e dados2. create table _generic_log ( tabela text not null, usuario text not null default current_setting('app.user_name'), ip_address text not null default current_setting('app.ip_address'), mac_address text not null default current_setting('app.mac_address'), data_hora timestamp not null default now(), operacao char not null check (operacao in ('I', 'U', 'D')), dados1 jsonb not null, dados2 jsonb null ); create index _generic_log_ind on _generic_log using brin (tabela); create or replace function check_generic_log() returns trigger as $$ begin if tg_op = 'INSERT' then insert into _generic_log ( tabela, operacao, dados1 ) select tg_table_name, tg_op::char, jsonb_object_agg( n.key, n.value ) from jsonb_each( to_jsonb( new ) ) n; elseif tg_op = 'DELETE' then insert into _generic_log ( tabela, operacao, dados1 ) select tg_table_name, tg_op::char, jsonb_object_agg( o.key, o.value ) from jsonb_each( to_jsonb( old ) ) o; else insert into _generic_log (tabela, operacao, dados1, dados2 ) select tg_table_name, tg_op::char, jsonb_object_agg( n.key, n.value ), jsonb_object_agg( o.key, o.value ) from jsonb_each( to_jsonb( new ) ) n join jsonb_each( to_jsonb( old ) ) o on n.key = o.key where (n.key = 'id') or (coalesce(n.value, o.value) is distinct from coalesce(o.value, n.value)); -- where (n.key = 'id' or n.value is distinct from o.value) and (n.key not in ( 'XXX','YYY' )); end if; return null; end; $$ language plpgsql; -- *************************************************** do $$ declare _comando text; declare _obj record; begin for _obj in select schemaname as schema, relname as tabela from pg_stat_user_tables loop -- insert or delete execute format('drop trigger if exists log_generic on %s;', ( _obj.schema || '.' || _obj.tabela)); execute format('create trigger log_generic after insert or delete on %s for each row execute function check_generic_log();', ( _obj.schema || '.' || _obj.tabela)); -- update --> somente se houve alteração ==> for each row WHEN (old.* is distinct from new.*) execute format('drop trigger if exists log_generic_update on %s;', ( _obj.schema || '.' || _obj.tabela)); execute format('create trigger log_generic_update after update on %s for each row WHEN (old.* is distinct from new.*) execute function check_generic_log();', ( _obj.schema || '.' || _obj.tabela)); end loop; end; $$
-
Trigger altera registro mesma tabela
pergunta respondeu ao Kellyton Armelin de Ronivaldo Lopes em PostgreSQL
boa noite, você tem que usar ":=" para mudar o campo status_op, CREATE OR REPLACE FUNCTION f_au_pcpcpr() RETURNS trigger AS $$ BEGIN IF NEW.pcpr_statuss_1 = 'C' THEN NEW.status_op := 'C'; END IF; RETURN NEW; END; $$ LANGUAGE plpgsql; -
Permissão negada em um schema
pergunta respondeu ao marcelo.santos.joinville de Ronivaldo Lopes em PostgreSQL
Boa noite, quando você executa o comando GRANT SELECT ON ALL TABLES IN SCHEMA, o usuário poderá executar o SELECT em todas tabelas criadas antes da sua execução, já não terá acesso as tabelas após a execução. Caso esteja executando o POSTGRESQL na versão 14, existem as roles pg_read_all_data e pg_write_all_data que dão acesso de leitura e escrita respectivamente, para as tabelas existentes e as que forem criadas após a sua execução. GRANT pg_read_all_data TO usuario; -
Problemas com a libpq.dll ao instalar PostgREST
pergunta respondeu ao Paulo Guimarães de Ronivaldo Lopes em PostgreSQL
Boa noite, eu uso o lazarus e o delphi, e tive problema para acessar o postgresql, e das diversas tentativas, a única que funcionou foi adicionar a pasta C:\Program Files\PostgreSQL\14\bin no path das variáveis de ambiente . -
Boa noite, tem um erro com a virgula no final da primeira linha. A virgula é usada quando for feita a atualização de mais de um campo e não precisa repetir a tabela cadmer depois do FROM. UPDATE cadmer SET nbm = inv.ncm FROM inv_31_12_2021_68504588000154_2 inv WHERE cadmer.Codigo = inv.Codigo;
-
Boa noite, eu usei um editor de texto e fiz a inclusão da linha vm.nr_hugepages=256 no final do arquivo /etc/sysctl.conf. Salvei e reinicializei a maquina e as 256 huge pages foram criadas. Esse é o primeiro passo, criar as huge pages. Execute o comando abaixo para verificar. grep '^HugePages' /proc/meminfo No meu notebook tenho Linux Mint rodando somente com o PostgreSQL. Acabei de ligá-lo e executei o comando acima para verificar o uso do HugePages, das 256 páginas criadas, 126 foram reservadas, variável HugePages_Rsvd, na tela da resposta anterior era 127, você criou somente 99 páginas, seja generoso, esse número tem que ser maior e com bastante folga. Você precisa entender o funcionamento do huge_pages no PostgreSQL. O padrão do huge_pages no PostgreSQL, é o try, significa que trabalha no modo protegido. Quando o PostgreSQL solicitar do sistema operacional páginas maiores e não houver disponibilidade, ele recebe as páginas de tamanho padrão e continua trabalhando normalmente, usufruindo das vantagens das huge pages quando disponíveis. Quando você muda para on, está forçando o PostgreSQL a trabalhar com o número limitado de huge pages criadas pelo sistema operacional, e deixará de funcionar sempre que uma solicitação de uma huge pages for negada, nem inicializa, e se já estiver funcionando, irá travar e será finalizado para liberar os recursos bloqueados, inclusive as huge pages. A opção try sempre vai usar huge pages, independente da quantidade, basta está disponível, já a opção on, faltou huge pages, travou, simples assim. Eu mudaria a configuração para on, somente se o equipamento for um servidor dedicado e possuir bastante memória ram, dezenas ou centenas de GB, ou seja, um servidor PARRUDO.
-
Bom dia, provavelmente o sistema operacional não está configurado para trabalhar com huge pages, execute o comando abaixo para fazer essa verificação. grep '^HugePages' /proc/meminfo Caso o HugePages_Total for igual a zero, você pode incluir a linha abaixo no arquivo /etc/sysctl.conf, no meu caso, estou configurando 256 páginas de 2MB, que é o tamanho padrão. vm.nr_hugepages=256 No link tem um pequeno tutorial. https://tureba.org/postgresql-linux.html

-
Bom dia, você tem que usar o utilitário para mudar a configuração padrão, no Linux é o configure, no Windows é o pg_config, veja no link abaixo na opção --disable-integer-datetimes. Acho se você executar o comando com o parâmetro indicado deve funcionar, e acredito que não pode haver nenhuma base de dados no servidor para fazer essa alteração, caso contrario poderá corromper as tabelas que possuem campos do tipo datetime. https://www.postgresql.org/docs/9.4/install-procedure.html pg_config --disable-integer-datetimes É recomendado atualizar todas as versões mais antigas do PostgreSQL, inclusive a versão 9.3, para uma versão que esteja recebendo suporte e atualizações. Eu tentaria atualizar para uma versão mais recente. Deu certo o pg_dump ? a mensagem tamanho 729 pode ser os 730 mil registros, por padrão o pg_dump não faz o backup de objetos grandes, talvez tenha que usar o parâmetro -b, devido a existência de tabelas com muitos registros e ativar a compactação -Z 9 . Boa sorte, se funcionar deixe uma mensagem.
-
Boa noite, a tabela parece está corrompida,tente executar o comando abaixo. vacuum FULL FREEZE ANALYZE "ihistcomercial_log" http://pgdocptbr.sourceforge.net/pg82/sql-vacuum.html
-
postgresql Substituir o Instr do Oracle para algo que funcione no PostGreSQL
pergunta respondeu ao Edson Vilhalba de Ronivaldo Lopes em PostgreSQL
segue outra versão create or replace function public.instr(_texto text, _busca text, _inicio int, _ocorrencia int) returns int as $$ declare len_busca int = length(_busca); resultado int = 0; begin with recursive busca( posicao,ocorrencia ) as ( select _inicio, 0 union all select strpos(substring(_texto, posicao), _busca) + posicao + len_busca - 1, ocorrencia+1 from busca where strpos(substring(_texto, posicao), _busca) > 0 and ocorrencia < _ocorrencia ) select posicao - len_busca into resultado from busca where ocorrencia = _ocorrencia; return coalesce(resultado, 0); end; $$ language plpgsql; -
postgresql Substituir o Instr do Oracle para algo que funcione no PostGreSQL
pergunta respondeu ao Edson Vilhalba de Ronivaldo Lopes em PostgreSQL
Boa noite, a função abaixo faz algo parecido, não faz o tramento que a função no oracle realiza em relação a parametros negativos, mas talvez possa ajuda-lo. create or replace function public.instr(_texto text, _busca text, _inicio int, _ocorrencia int) returns int as $$ declare ocorrencia int = 0; posicao int = 0; soma int = _inicio; tamanho int = length(_busca); begin while ocorrencia < _ocorrencia loop posicao := strpos(substring(_texto, soma), _busca); if posicao > 0 then soma := soma + posicao + tamanho - 1; ocorrencia := ocorrencia + 1; else exit; end if; end loop; if ocorrencia > 0 then return soma - tamanho; else return 0; end if; end; $$ language plpgsql; -
Como descobrir qual tabela um registro foi incluido ou modificado [fechada]
pergunta respondeu ao Thiago Machado Alves de Ronivaldo Lopes em PostgreSQL
Boa tarde, você pode criar uma única tabela de log e criar uma trigger genérica que seja disparada por todas as tabelas do sistema, sem afetar as triggers já existentes. No meu caso o campo chave de todas as tabelas é o id, e no update incluo na tabela de log dois registros, o antes e o depois de atualizado, e somente o id e os campos que foram modificados. Para facilitar pode fazer o update igual a insert. create table generic_log ( tabela text not null, usuario text not null default current_setting('app.user_name'), ip_address text not null default current_setting('app.ip_address'), mac_address text not null default current_setting('app.mac_address'), data_hora timestamp not null default now(), operacao char not null check (operacao in ('I', 'U', 'D')), dados jsonb not null ) with (oids=false); create index generic_log_ind on generic_log using brin (tabela); create or replace function check_generic_log() returns trigger as $$ begin if tg_op = 'DELETE' then insert into public.generic_log ( tabela, operacao, dados ) values ( tg_table_name, tg_op::char, to_jsonb(old) ); elseif tg_op = 'INSERT' then insert into public.generic_log ( tabela, operacao, dados ) values ( tg_table_name, tg_op::char, to_jsonb(new) ); else insert into public.generic_log (tabela, operacao, dados) select tg_table_name, tg_op::char, jsonb_object_agg( o.key, o.value ) from jsonb_each( to_jsonb( old ) ) o join jsonb_each( to_jsonb( new ) ) n on o.key = n.key where (o.key = 'id' or o.value <> n.value) and (o.key not in ( 'XXX','YYY' )); insert into public.generic_log (tabela, operacao, dados) select tg_table_name, tg_op::char, jsonb_object_agg( n.key, n.value ) from jsonb_each( to_jsonb( old ) ) o join jsonb_each( to_jsonb( new ) ) n on o.key = n.key where (o.key = 'id' or o.value <> n.value) and (o.key not in ( 'XXX','YYY' )); end if; return null; end; $$ language plpgsql; create trigger log_generic after insert or update or delete on tabela_a for each row execute function check_generic_log(); create trigger log_generic after insert or update or delete on tabela_b for each row execute function check_generic_log(); create trigger log_generic after insert or update or delete on tabela_c for each row execute function check_generic_log(); Executar o comando anterior para todas as tabelas do sistema.