Pesquisar na Comunidade
Mostrando resultados para as tags ''csv''.
Encontrado 14 registros
-

Erro de acentuação em fgetcsv
uma questão postou edionas Repositório de Scripts - Ajax, JS, XML, DOM
Bom dia, estou desenvolvendo uma plataforma que busca e exibe dados de determinado portal da transparência através de arquivo CSV, entretendo, o cabeçalho do arquivo inclui alguns dados acentuados (Função, Admissão, Líquido...) e não consigo fazer com que esses dados sejam exibidos pois aparece uma mensagem de erro. <table class="table"> <tr> <th>1Matricula</th> <th>2Nome</th> <th>5CPF</th> <th>6Secretaria</th> <th>8Função</th> <th>9Natureza</th> <th>10CH</th> <th>11Admissão</th> <th>12Líquido</th> </tr> <?php /*ini_set('display_errors', 0 ); error_reporting(0);*/ $delimitador = ';'; $cerca = '"'; $f = fopen('http://www.sstransparenciamunicipal.net/transparencia/apicsv.php?entcod=18&mes=1&ano=2018&tabela=18.csv', 'r'); if ($f) { $cabecalho = fgetcsv($f, 0, $delimitador, $cerca); while (!feof($f)) { $linha = fgetcsv($f, 0, $delimitador, $cerca); if (!$linha) { continue; } $registro = array_combine($cabecalho, $linha); echo "<tr>"; echo "<td>"; echo $registro['ID Servidor'].PHP_EOL; echo "</td>"; echo "<td>"; echo $registro['Servidor'].PHP_EOL; echo "</td>"; echo "<td>"; echo $registro['CPF'].PHP_EOL; echo "</td>"; echo "<td>"; echo $registro['Secretaria'].PHP_EOL; echo " / "; echo $registro['Setor'].PHP_EOL; echo "</td>"; echo "<td>"; echo $registro['Função'].PHP_EOL; echo "</td>"; echo "<td>"; echo $registro['Natureza'].PHP_EOL; echo "</td>"; echo "<td>"; echo $registro['CH'].PHP_EOL; echo "</td>"; echo "<td>"; echo $registro['Admissão'].PHP_EOL; echo "</td>"; echo "<td>"; echo $registro['Líquido'].PHP_EOL; echo "</td>"; echo "</tr>"; } fclose($f); } ?> -
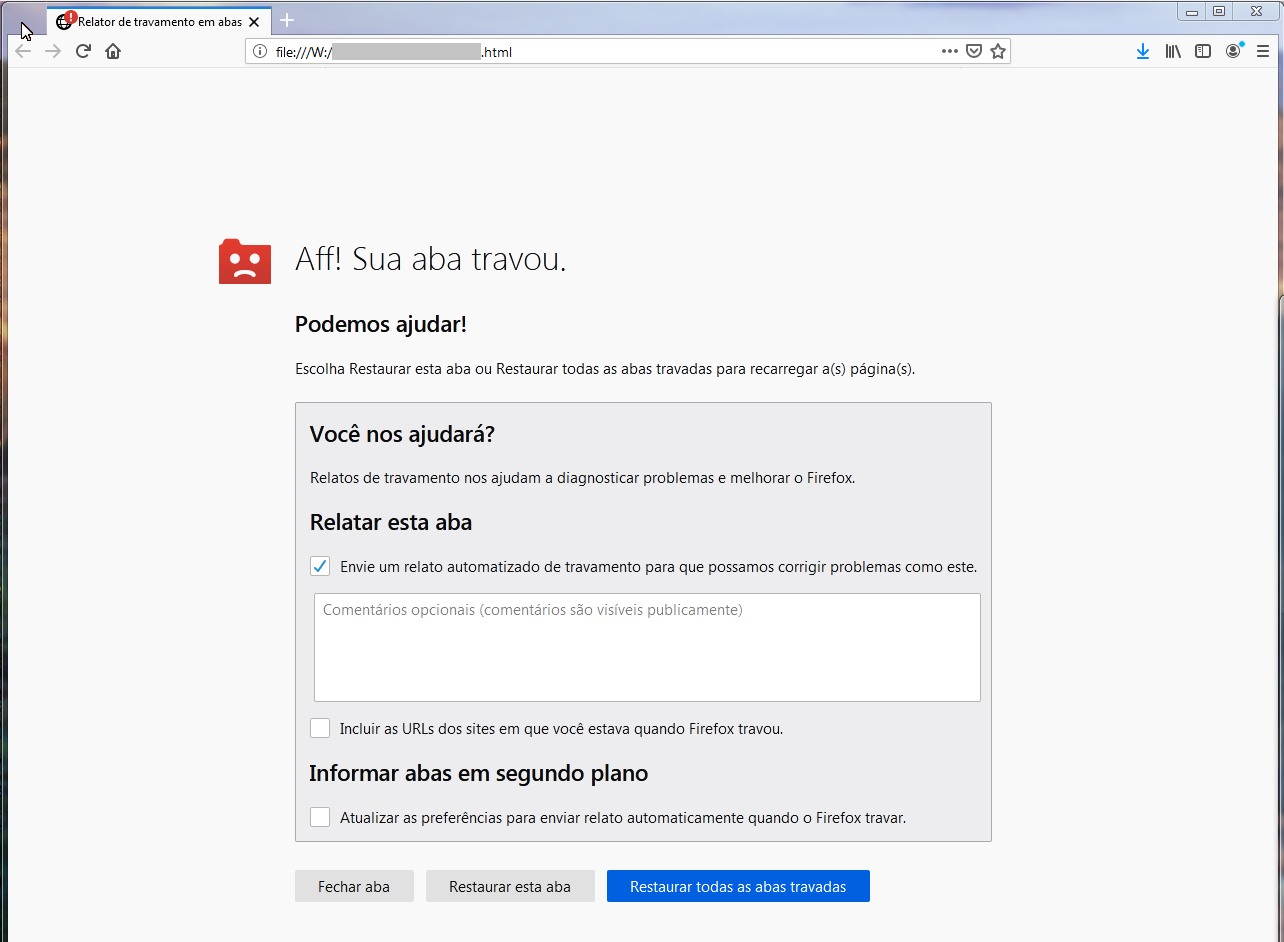
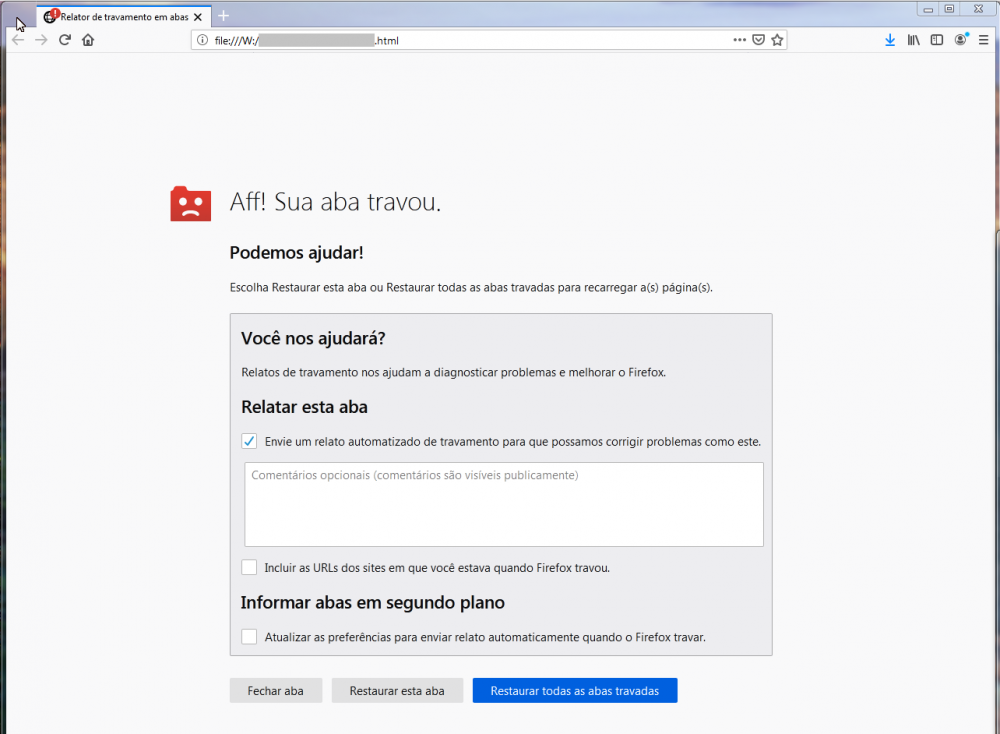
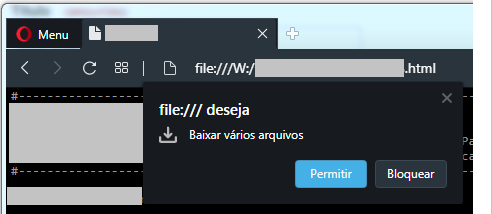
Caros amigos, Fiz uma aplicação usando HTML simples, CSS e Javascript com o propósito de criar uma tabela em HTML e fazer o download em formato CSV dessa tabela automaticamente a cada 1 minuto. Até aqui tudo bem, funciona perfeitamente. O problema é: 1: Usando o navegador firefox, após 192 download's correspondentes a 3h e 12 minutos exatamente, a pagina trava e fecha a minha aplicação. Ver imagem "Firefox"! 2: Usando outros navegadores como Chrome ou Opera, aparece uma mensagem pedindo para permitir o download automático a todo instante. Mesmo eu clicando em permitir e configurando lá nas configurações do navegador, mesmo assim, a mensagem aparece ao longo do dia várias vezes. O problema é que, enquanto eu não clicar nessa mensagem confirmando em 'Permitir', os arquivos CSV não são baixados. Aí durante a madrugada eu perco muitos dados. Ver imagem "Opera"! Diante do exposto, peço a ajuda dos amigos para uma solução. Qualquer sugestão é bem vinda!
-
Tenho tentado separar as colunas de uma planilha do excel salva em csv, no entanto o programa não esta retornando as colunas separadamente. o problema é que o arquivo do excel não esta sendo salvo com as colunas separadas, o programa está reconhecendo apenas as linhas. como solucionar isso? ['Erenice Santo Santos;;5587999320116'] ['Lucikleia Silva;;5587996083111'] ['Auda Pereira;;5587996683884'] ['Carlin Furtado;;5587999619122'] ['Zenilda Martins;;5587996332506'] ['Morgana Casusa;;5583996334018'] ['Leonizia Moreira;;5587996216471'] import csv with open('pasta.csv', 'r') as csv_file: csv_reader = csv.reader(csv_file) for line in csv_reader: print(line) #usando o este código o programa retorna a lista acima. import csv with open('pasta.csv', 'r') as csv_file: csv_reader = csv.reader(csv_file) for line in csv_reader: print(line[1]) #quero imprimir apenas a coluna com os números, mas quando uso este metodo o programa retorna um erro.
-
Olá, Gostava de ajuda para resolver um problema. Tenho um ficheiro csv com um campo décimal (ex. 10,003) (`id`,`nome`,`campo_decimal_1`) Na base de dados o campo "campo_decimal" está definido como: Decimal(10,3) Estou a importar os dados com a seguinte query: LOAD DATA local infile 'C:/tmp/file.csv' INTO TABLE `tabela_a` FIELDS TERMINATED BY ';' OPTIONALLY ENCLOSED BY '"' ESCAPED BY '' LINES TERMINATED BY '\n' (`id`,`nome`,`campo_decimal_1`) Depois de importar, os dados do campo decimal aparecem assim - 10.000 Como posso resolver esta questão? Obrigado Antonio
-

Identificar excesso de delimitador em arquivo
uma questão postou etspaz Repositório de scripts - Python
Bom dia! Estou utilizando python para efetuar a carga de arquivos num banco. E estou com o seguinte problema. O arquivo [e delimitado por ;. então usei a funcao: dados = csv.reader(open('xxx.txt','r'),delimiter=';') Mas ocorre que em alguns campos contem o caractere ; no texto... e o python separa o campo em duas colunas... ai bagunca td. já me informaram que as areas que geram os dados não alteram para incluir um qualificador de texto, que resolveria meu problema. alguém j[a teve problema parecido? Consigo descobrir em qual linha tem mais delimitadores do que o normal, mas como tem mais de um campo que pode ter o caractere ; não consigo definir qual caractere que devo eliminar. Desde já agradeco a atencao. Att, Ernesto Teodoro da SIlva -
O meu sistema funciona da seguinte maneira: Tenho 1517 sensores que armazenam em cada dia do ano, uma certa precipitação que é medida de três em três horas durante todo o dia. Tenho uma tabela chamada pontos que tem as seguintes colunas: gid (que é a chave primária de cada sensor), latitude, longitude. E tenho uma outra tabela chamada historico que tem as seguintes colunas: id (que é a chave primária de cada historico), datah, horah, precipitacaoh, gidgeo_fk (que é a chave estrangeira que represente os sensores). Fiz um script em python para armazenar cada sensor em um arquivo chamado sensor.csv, que armazena também cada hora distinta em outro arquivo chamado data.csv, e armazena também a precipitação e hora em arquivos separados. Depois crio um arquivo que faz um relacionamento entre todos estes pontos. O problema é que são 1517 sensores, e eu estava testando isso pra ver se dava tudo certo para 1 sensor apenas, ou seja, ele pega um sensor e armazena todo o histórico deste sensor em arquivos, juntamente com os relacionamentos, mas isso está demorando 192 minutos mais ou menos, PARA APENAS UM SENSOR, pra fazer isso para 1517 sensores iria levar mais de 200 dias! Gostaria que alguém me ajudasse a diminuir este tempo drasticamente, sem ter que mexer em index e etc. Creio que seja o jeito que estou programando o meu script, mas não sei onde estou programando errado. Alguém pode me ajudar? Abaixo está o código do meu script. import psycopg2 import csv conn = psycopg2.connect("\ dbname='bdTrmmTest'\ user='postgres'\ host='127.0.0.1'\ password='1234'\ "); #input() csv_sensor = open('sensor.csv',"w") csv_data = open('data.csv',"w") csv_hora = open('hora.csv',"w") csv_precipitacao = open('precipitacao.csv',"w") csv_rels = open('rels.csv',"w") labelSensor = 'Sensor' labelData = 'Data' labelHora = 'Hora' labelPrecip = 'Precipitacao' labelAS = 'AS' labelEM = 'EM' labelREGISTROU = 'REGISTROU' contGeral = 0 c = conn.cursor() c1 = conn.cursor() c2 = conn.cursor() c3 = conn.cursor() writer = csv.writer(csv_sensor) writer2 = csv.writer(csv_data) writer3 = csv.writer(csv_hora) writer4 = csv.writer(csv_precipitacao) writer5 = csv.writer(csv_rels) writer.writerow(('name:ID', 'IDPostgres', 'latitude', 'longitude', ':LABEL')) writer2.writerow(('data:ID','vdata',':LABEL')) writer3.writerow(('hora:ID','vhora',':LABEL')) writer4.writerow(('precip:ID','valor',':LABEL')) writer5.writerow((':START_ID',':END_ID',':TYPE')) c.execute("SELECT DISTINCT gid, latitude, longitude FROM pontos LIMIT 1") c1.execute("SELECT DISTINCT datah FROM historico") c3.execute("SELECT DISTINCT horah FROM historico") records = c.fetchall() records1 = c1.fetchall() records3 = c3.fetchall() for contSensor in records: print("Escrevendo sensor %d"%(contSensor[0])) writer.writerow((contGeral,contSensor[0], contSensor[1], contSensor[2], labelSensor)) print("Sensor %d escrito"%(contSensor[0])) contSensorFlag = contGeral contGeral += 1 for contReg in records1: contData = contGeral print("Escrevendo data %s"%(contReg[0])) writer2.writerow((contGeral, contReg[0], labelData)) print("Data %s escrita"%(contReg[0])) #escreve relacionamento entre sensor e data print("Escrevendo relacionamento entre sensor %d e data %s"%(contSensor[0],contReg[0])) writer5.writerow((contSensorFlag,contData, labelEM)) print("Relacionamento entre sensor %d e data %s escrito"%(contSensor[0],contReg[0])) contGeral += 1 for contReg3 in records3: c2.execute("SELECT precipitacaoh FROM historico WHERE gidgeo_fk = %d AND datah = '%s' AND horah = %d"%(contSensor[0],contReg[0],contReg3[0])) records2 = c2.fetchall() contHora = contGeral print("Escrevendo hora %d"%(contReg3[0])) writer3.writerow((contGeral, contReg3[0], labelHora)) print("Hora %d escrita"%(contReg3[0])) contGeral += 1 #escreve relacionamento entre data e hora print("Escrevendo relacionamento entre data %s e hora %d"%(contReg[0],contReg3[0])) writer5.writerow((contData,contHora, labelAS)) print("Relacionamento entre data %s e hora %d escrito"%(contReg[0],contReg3[0])) for contReg2 in records2: contPrecip = contGeral print("Escrevendo precipitacao %s"%(contReg2[0])) writer4.writerow((contGeral,contReg2[0], labelPrecip)) print("Precipitacao %s escrita"%(contReg2[0])) #escreve relacionamento entre hora e precipitacao print("Escrevendo relacionamento entre hora %d e precipitacao %s"%(contReg3[0],contReg2[0])) writer5.writerow((contHora,contPrecip, labelREGISTROU)) print("Relacionamento entre hora %d e precipitacao %s escrito"%(contReg3[0],contReg2[0])) contGeral += 1 csv_sensor.close() csv_data.close() csv_hora.close() csv_precipitacao.close() csv_rels.close() print(open('sensor.csv', 'rt').read())
-
O meu sistema funciona da seguinte maneira: Tenho 1517 sensores que armazenam em cada dia do ano, uma certa precipitação que é medida de três em três horas durante todo o dia. Tenho uma tabela chamada pontos que tem as seguintes colunas: gid (que é a chave primária de cada sensor), latitude, longitude. E tenho uma outra tabela chamada historico que tem as seguintes colunas: id (que é a chave primária de cada historico), datah, horah, precipitacaoh, gidgeo_fk (que é a chave estrangeira que represente os sensores). Fiz um script em python para armazenar cada sensor em um arquivo chamado sensor.csv, que armazena também cada hora distinta em outro arquivo chamado data.csv, e armazena também a precipitação e hora em arquivos separados. Depois crio um arquivo que faz um relacionamento entre todos estes pontos. O problema é que são 1517 sensores, e eu estava testando isso pra ver se dava tudo certo para 1 sensor apenas, ou seja, ele pega um sensor e armazena todo o histórico deste sensor em arquivos, juntamente com os relacionamentos, mas isso está demorando 192 minutos mais ou menos, PARA APENAS UM SENSOR, pra fazer isso para 1517 sensores iria levar mais de 200 dias! Gostaria que alguém me ajudasse a diminuir este tempo drasticamente, sem ter que mexer em index e etc. Creio que seja o jeito que estou programando o meu script, mas não sei onde estou programando errado. Alguém pode me ajudar? Abaixo está o código do meu script. import psycopg2 import csv conn = psycopg2.connect("\ dbname='bdTrmmTest'\ user='postgres'\ host='127.0.0.1'\ password='1234'\ "); #input() csv_sensor = open('sensor.csv',"w") csv_data = open('data.csv',"w") csv_hora = open('hora.csv',"w") csv_precipitacao = open('precipitacao.csv',"w") csv_rels = open('rels.csv',"w") labelSensor = 'Sensor' labelData = 'Data' labelHora = 'Hora' labelPrecip = 'Precipitacao' labelAS = 'AS' labelEM = 'EM' labelREGISTROU = 'REGISTROU' contGeral = 0 c = conn.cursor() c1 = conn.cursor() c2 = conn.cursor() c3 = conn.cursor() writer = csv.writer(csv_sensor) writer2 = csv.writer(csv_data) writer3 = csv.writer(csv_hora) writer4 = csv.writer(csv_precipitacao) writer5 = csv.writer(csv_rels) writer.writerow(('name:ID', 'IDPostgres', 'latitude', 'longitude', ':LABEL')) writer2.writerow(('data:ID','vdata',':LABEL')) writer3.writerow(('hora:ID','vhora',':LABEL')) writer4.writerow(('precip:ID','valor',':LABEL')) writer5.writerow((':START_ID',':END_ID',':TYPE')) c.execute("SELECT DISTINCT gid, latitude, longitude FROM pontos LIMIT 1") c1.execute("SELECT DISTINCT datah FROM historico") c3.execute("SELECT DISTINCT horah FROM historico") records = c.fetchall() records1 = c1.fetchall() records3 = c3.fetchall() for contSensor in records: print("Escrevendo sensor %d"%(contSensor[0])) writer.writerow((contGeral,contSensor[0], contSensor[1], contSensor[2], labelSensor)) print("Sensor %d escrito"%(contSensor[0])) contSensorFlag = contGeral contGeral += 1 for contReg in records1: contData = contGeral print("Escrevendo data %s"%(contReg[0])) writer2.writerow((contGeral, contReg[0], labelData)) print("Data %s escrita"%(contReg[0])) #escreve relacionamento entre sensor e data print("Escrevendo relacionamento entre sensor %d e data %s"%(contSensor[0],contReg[0])) writer5.writerow((contSensorFlag,contData, labelEM)) print("Relacionamento entre sensor %d e data %s escrito"%(contSensor[0],contReg[0])) contGeral += 1 for contReg3 in records3: c2.execute("SELECT precipitacaoh FROM historico WHERE gidgeo_fk = %d AND datah = '%s' AND horah = %d"%(contSensor[0],contReg[0],contReg3[0])) records2 = c2.fetchall() contHora = contGeral print("Escrevendo hora %d"%(contReg3[0])) writer3.writerow((contGeral, contReg3[0], labelHora)) print("Hora %d escrita"%(contReg3[0])) contGeral += 1 #escreve relacionamento entre data e hora print("Escrevendo relacionamento entre data %s e hora %d"%(contReg[0],contReg3[0])) writer5.writerow((contData,contHora, labelAS)) print("Relacionamento entre data %s e hora %d escrito"%(contReg[0],contReg3[0])) for contReg2 in records2: contPrecip = contGeral print("Escrevendo precipitacao %s"%(contReg2[0])) writer4.writerow((contGeral,contReg2[0], labelPrecip)) print("Precipitacao %s escrita"%(contReg2[0])) #escreve relacionamento entre hora e precipitacao print("Escrevendo relacionamento entre hora %d e precipitacao %s"%(contReg3[0],contReg2[0])) writer5.writerow((contHora,contPrecip, labelREGISTROU)) print("Relacionamento entre hora %d e precipitacao %s escrito"%(contReg3[0],contReg2[0])) contGeral += 1 csv_sensor.close() csv_data.close() csv_hora.close() csv_precipitacao.close() csv_rels.close() print(open('sensor.csv', 'rt').read())
-
Estou com um trabalho de Estrutura de Dados para ser feito, mas estou tendo muita dificuldade em ler um arquivo CSV e separar as informações em variáveis. O problema deve ser iniciado desta maneira para que depois ainda seja adicionado mais clientes, excluir e tudo mais. Alguém poderia ajudar? O inicio do meu programa (a função do arquivo), está até agora desta maneira: #include <stdio.h> #include <stdlib.h> #include <string.h> char string [1000]; float total; FILE * pFile; char linha[200]; struct estrutura { int aux; char nome[40]; char endereco[40]; char cidade[40]; char pais[20]; char cep[10]; char nasc[12]; char telefone[14]; float total[20]; }; struct estrutura cliente[200]; int menu(); int menu2(); void arquivo(); void adicionar(); void alterar(); void excluir(); void exibir(); void pesquisar(); void listarnome(); void listarcodigo(); void listartotal(); int contar(); char *tmp; main() { system("cls"); menu(); //a função arquivo é uma opção do menu } //---------------------------------------------- //LEITURA DE ARQUIVO //---------------------------------------------- void arquivo() { pFile = fopen( "11_ProjetoPratico_ControleClientes_clientes.csv", "r" ) ; int i = 0; while (fgets(string, 1000, pFile) != NULL) { tmp = strtok(linha, ";"); cliente[i].aux = atoi(tmp); //atoi for int tmp = strtok(NULL, ";"); //use strcpy for char strcpy(cliente[i].nome,tmp); printf("%s", cliente[i].nome); tmp = strtok(NULL, ";"); strcpy(cliente[i].endereco,tmp); tmp = strtok(NULL, ";"); strcpy(cliente[i].cidade, tmp); tmp = strtok(NULL, ";"); strcpy(cliente[i].pais, tmp); tmp = strtok(NULL, ";"); strcpy(cliente[i].cep, tmp); tmp = strtok(NULL, ";"); strcpy(cliente[i].nasc, tmp); tmp = strtok(NULL, ";"); strcpy(cliente[i].telefone, tmp); printf("index i= %i ID: %i, %s, %s, %s, %s, %s, %s, %s, %f \n",i, cliente[i].aux , cliente[i].nome, cliente[i].endereco , cliente[i].cidade, cliente[i].pais, cliente[i].cep, cliente[i].nasc, cliente[i].telefone, cliente[i].total); i++; } //free(buf); fclose(pFile); } Obrigado desde já!
-
Olá, Estou querendo fazer o seguinte: 1. Tenho uma tabela com dados COL1 COL2 COL3 COL4 COL5 COL6 1 AAA OPEN 1000 51 01-10-2016 2 AAA OPEN 1000 51 10-10-2016 3 AAA OPEN 1000 51 02-10-2016 4 AAA OPEN 1000 51 10-10-2016 5 AAA OPEN 1000 51 10-10-2016 6 AAA OPEN 1000 51 01-10-2016 2. criar tarefa que importa um csv de um folder (c:\localização_do_ficheiro) 3. Adicionar à tabela linhas não existentes e substituir linhas que tenham valor igual à coluna COL1 4. trarefa deverá ocorrer a cada 2 horas alguém pode ajudar? Obrigado Antonio
-
Olá, sou novata no fórum e no php. Gostaria de saber se existe a possibilidade de upar um arquivo .csv no site dando a opção do cliente alterar o delimitador que foi setado no próprio arquivo. Exemplo: se o cliente estiver subindo um arquivo .csv com delimitador "," e quiser alterar para ";" ou vice e versa, é possível? Se sim, como posso fazer? Agradeço desde já!
-
Boa Tarde Galera. Vou tentar explicar essa minha grande dúvida da maneira mais clara possível, vamos lá: Tenho um sistema que recebe um UPLOAD de um arquivo .CSV e insere corretamente no banco de dados todas as colunas e linhas necessárias, até que um cliente chegou a mim me questionando sobre as pastas que eram duplicadas toda vez que ele fazia um novo UPLOAD("e;Pastas duplicadas seriam digamos 2 ou mais vezes o mesmo CNPJ e CPF inseridos), então oque propus a ele foi: Sempre que houver um novo upload ele confere se o CPF/CNPJ já está inserido no banco de dados. 1º -) Se o CPF/CNPJ não estiver inserido no banco de dados ele vai e criar o INSERT de registros normalmente. 2º-) Se o CPF/CNPJ já estiver inserido, ele cria um UPDATE nos registros, e faz o UPDATE dos arquivos com esse novo UPLOAD. Espero que entendam essa minha duvida. <?php include "../_conexao/conexao.php"; //Transferir o arquivo if (isset($_POST['submit'])) { //Importar o arquivo transferido para o banco de dados $sql = mysqli_query($conexao,"SELECT cpf_cnpj FROM semaforo"); $handle = fopen($_FILES['filename']['tmp_name'], "r"); while (($data = fgetcsv($handle, 1000, ";")) !== FALSE) { if ($data[0] != 'situacao_primaria' && !empty($handle)) { $import="INSERT into semaforo(id,situacao_primaria,status,data_indicacao,tipo_de_indicacao,tipo_de_distribuicao,categoria,codigo_penumper,nome_do_cliente,cpf_cnpj,negociadores,tipo_pessoa_cliente,uf,cep,municipio_do_cliente,advogado_gestor_interno,numero_operacao,sistema_origem,numero_operacao_origem,familia_do_produto,codigo_produto,nome_do_produto,codigo_agencia,nome_agencia,descricao_segmento,segmento_secundario,descricao_segmento_secundario,situacao_secundaria,data_recebimento,data_credito_liquidacao,valor_da_operacao,valor_transferido_para_creli,valor_da_divida,valor_saldo_contabil,qdt_dias_atraso,nome_da_garantia,ajuizado,codigo_do_ajuizamento,valor_ajuizado,tipo_de_acao,motivo_da_acao,avalista_nome,avalista_cpf_cnpj,avalista_tipo_pessoa,saldo_cm1,recup_judicial_falencia,escob_adm,data_inclusao_escob)values(null,'$data[0]','$data[1]','$data[2]','$data[3]','$data[4]','$data[5]','$data[6]','$data[7]','$data[8]','$data[9]','$data[10]','$data[11]','$data[12]','$data[13]','$data[14]','$data[15]','$data[16]','$data[17]','$data[18]','$data[19]','$data[20]','$data[21]','$data[22]','$data[23]','$data[24]','$data[25]','$data[26]','$data[27]','$data[28]','$data[29]','$data[30]','$data[31]','$data[32]','$data[33]','$data[34]','$data[35]','$data[36]','$data[37]','$data[38]','$data[39]','$data[40]','$data[41]','$data[42]','$data[43]','$data[44]','$data[45]','$data[46]')"; mysqli_query($conexao, $import) or die(mysqli_error($conexao)); } } fclose($handle); print "<center>Transferir <b>SEMÁFORO</b> por arquivo CSV selecione o arquivo clicando no botão <b>escolher arquivo</b>, e envie clicando no botão <b>upload</b>.</center><br /><br />\n"; print "<form enctype='multipart/form-data' action='#' method='post'>"; print "<center><input size='50' type='file' name='filename'></center><br /><br />\n"; print "<center><input type='submit' name='submit' value='Upload'></center></form>"; //Visualizar formulário de transferência } else { print "<center>Transferir <b>SEMÁFORO</b> por arquivo CSV selecione o arquivo clicando no botão <b>escolher arquivo</b>, e envie clicando no botão <b>upload</b>.</center><br /><br />\n"; print "<form enctype='multipart/form-data' action='#' method='post'>"; print "<center><input size='50' type='file' name='filename'></center><br /><br />\n"; print "<center><input type='submit' name='submit' value='Upload'></center></form>"; } ?> Esse é meu arquivo, espero que consigam me ajudar. Agradeço desde já;
-
Trabalho com vídeo e procuro parceiros que dominem as ferramentas do Google Maps API´s e sistemas de GPS para desenvolvimento de um produto técnico de multimídia. Aguardo contatos dos interessados. Obrigado.
-
Trabalho com vídeo e procuro parceiros que dominem as ferramentas do Google Maps API´s e sistemas de GPS para desenvolvimento de um produto técnico de multimídia. Aguardo contatos dos interessados. Obrigado.
-
Boa tarde, Sou novo no uso da linguagem perl e estou querendo algumas sugestões de como gerar um script para realizar a filtragem e soma de alguns dados que possuo em uma tabela .csv. Possuo uma tabela com colunas de valores aferidos para N individuos. Nessa tabela, um mesmo individuo pode ter mais de um valor para cada medida. Ex.: individuo medida1 medida2 1 5 6 1 6 7 1 10 12 2 11 13 2 12 15 3 15 16 3 17 18 3 19 25 A partir dos dados, eu gostaria de gerar um arquivo contendo a soma dos valores, de cada indivíduo, para uma determinada medida em um determinado intervalo. Por exemplo, a soma dos valores da medida2 entre 15 e 20 para os três indivíduos. Que nesse caso seria: individuo 1=0; individuo2= 15; individuo3= 34. Qual forma vocês sugerem ? Muito obrigado.