Pesquisar na Comunidade
Mostrando resultados para as tags ''postgresql''.
Encontrado 52 registros
-
 Olá Pessoal, Eu estou buscando alguma solução para substituir o INSTR do Oracle para alguma que funcione no PostGreSQL. Exemplo temos o texto: "Buscando uma palavra" Se utilizarmos instr('Buscando uma palavra',' ',1,2)), como podem ver eu coloquei na função para que ela me retorne o tamanho até o segundo espaço, no caso irá retornar um tamanho 13. No caso no PostGreSQL temos a função Position, porém o problema dela é que ela não tem parâmetros para eu buscar como o INSTR que seria "Até o segundo espaço", o Position se eu colocar para buscar até o espaço ele só vai até o primeiro e não tem um parâmetro para eu colocar "quero até o segundo espaço". Poderiam me ajudar? Desde já agradecido!
Olá Pessoal, Eu estou buscando alguma solução para substituir o INSTR do Oracle para alguma que funcione no PostGreSQL. Exemplo temos o texto: "Buscando uma palavra" Se utilizarmos instr('Buscando uma palavra',' ',1,2)), como podem ver eu coloquei na função para que ela me retorne o tamanho até o segundo espaço, no caso irá retornar um tamanho 13. No caso no PostGreSQL temos a função Position, porém o problema dela é que ela não tem parâmetros para eu buscar como o INSTR que seria "Até o segundo espaço", o Position se eu colocar para buscar até o espaço ele só vai até o primeiro e não tem um parâmetro para eu colocar "quero até o segundo espaço". Poderiam me ajudar? Desde já agradecido! -
Um cliente esta com uma lentidao em um Select ma espera de uns 10 Segundos e eu tenho o mesmo banco de dados no meu servidor com a mesma versao do banco de dados e o Select é praticamente instantaneo menos de 1s alguém já teve um problema desses agradeço a Ajuda Obrigado
-
Gostaria de saber si é possível configurar o PostgreSQL para case insensitive.
-
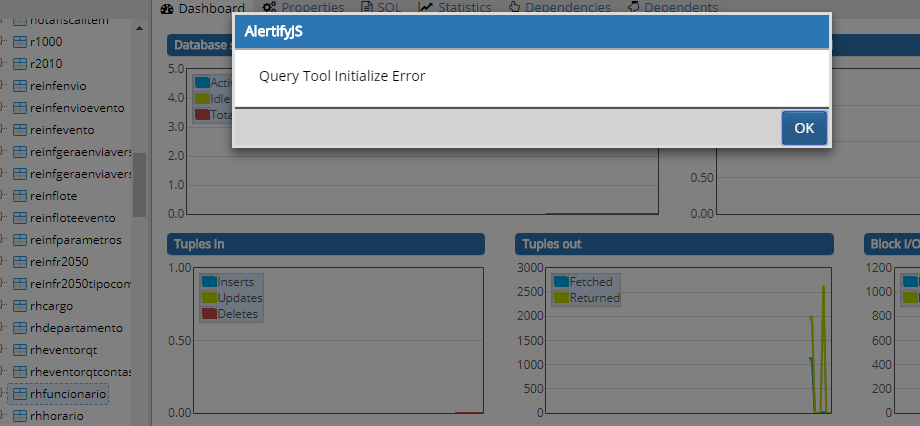
Alguém sabe como resolver o erro "Query Tool Initialize Error" aparece quando tenta abrir a tela de consulta no PgAdmin 4 com PostgreSQL 10?
-
Quando tento rodar um script no banco usando o pgAdmin 4, retorna este erro: "Query Tool Initialize Error".
-
Bom dia, criei um pequeno sistema em PHP de inserção de arquivos PDF numa base de dados PostgreSQL. Como o sistema é pequeno, não terei problemas de performance e preocupação com backups em diretório ou se alguém vai deletar a imagem no diretório. O tipo de dado do PostgreSQL que insiro o arquivo é o Bytea. No computador de casa, realizo o upload normal, o arquivo abre normal, mas no notebook e computador do trabalho ficam corrompidos. Uma coincidência é que nos computadores que dão erro, o sistema operacional é de 64BITs e consequentemente os programas instalados tem uma versão diferente. O erro que acontece é o seguinte: O arquivo fica corrompido e o PDF não consegue realizar a leitura. Pois bem, realizei o teste da funcionalidade do sistema em 3 computadores distintos. Dos 3 computadores, em apenas 1 computador, funcionou corretamente. Segue a configuração dos computadores: Desde já agradeço se alguém puder me ajudar. Obrigado

-
Senhores, boa tarde. Estou iniciando na linguagem PHP. Preciso desenvolver uma pequena aplicação que guarde no banco de dados PostgreSQL arquivos em PDF. Depois da inserção, realizar a consulta. Informações: 1. O Campo que receberá o arquivo PDF no Postgresql tem que ser do tipo Bytea; 2. Meu sistema operacional é Windows 10; 3. Meu PostgreSQl é o 9.6, pgadmin 4; 4. Como servidor, utilizo o WampServer; e 5. A inserção até funciona, pelo menos quando consulto no Postgres aparece o nome do arquivo na base de dados, mas para realmente saber se ele está lá, preciso consultá-lo, mas não consigo fazer a consulta. ATENÇÃO: Sei que não é a melhor prática, salvar arquivos no BD, que o melhor a fazer era salvar o caminho e guardar os arquivos em diretórios, porém o sistema não é gigante e os arquivos são pequenos, por isso não terei problemas com desempenho do Banco entre outros, portanto, não precisa responder apenas que não é uma boa prática, preciso de uma solução e agradeço a todos pela colaboração... Seguem meus códigos: Tenho no Banco de Dados a seguinte estrutura: (É apenas um ambiente de testes, os campos reais serão diferentes) BD_Revista Tabela tb102_documento colunas: documentoid serial revistaid integer codsecao character(2) documento bytea formulario.html <HTML> <HEAD> <TITLE>Formulário de Cadastro</TITLE> </HEAD> <BODY> <center> <form name = "frmCadastro" method="POST" action = "cadastrar.php"> Documento:<input type="text" size="20" name = "documentoid"><BR> Revista: <input type="text" size="20" name = "revistaid"><BR> Codigo da Seção:<input type="text" size="20" name = "codsecao"><BR> Documento: <input type="file" name = "documento"><BR> <input type="submit" value="Gravar"> </form> <center> </BODY> </HTML> cadastrar.php <?php //Verifica se existe o arquivo executa.php para poder incluí-lo if (file_exists("executa.php")){ include("executa.php"); } if (!file_exists("executa.php")){ $msgErro = "<center><font color='#FF0000'><b>"; $msgErro .= "Não será possível executar nenhuma ação no Banco de Dados!<br>"; $msgErro .= "Porque não existe o arquivo 'executa.php'."; $msgErro .= "</b></font></center>"; echo "<br><br>"; echo $msgErro; echo "<br>"; exit; } //recebendo os dados do formulário $documentoid = $_POST['documentoid']; $revistaid = $_POST['revistaid']; $codsecao = $_POST['codsecao']; $documento = $_POST['documento']; //if ($revistaid == ""){ // echo "<center>O codigo id da revista deve ser informado!</center>"; // echo "<center><input type = 'button' value = 'Voltar' name = 'btnVoltar' Onclick = 'javascript:history.go(-1)'></center>"; //} //if ($nroano == ""){ // echo "<center>O ano deve ser informado!</center>"; // echo "<center><input type = 'button' value = 'Voltar' name = 'btnVoltar' Onclick = 'javascript:history.go(-1)'></center>"; //} //Montando a String de SQL $Sql = "Insert into tb102_documento(documentoid, revistaid, codsecao, documento) values('$documentoid', '$revistaid', '$codsecao', '$documento')"; //Chamando a função, e passando como parâmetro a String de SQL $Resultado = executa($Sql); if ($Resultado){ echo "<center>Cadastro efetuado com sucesso!</center>"; echo "<center><input type = 'button' value = 'Voltar' name = 'btnVoltar' Onclick = 'javascript:history.go(-1)'></center>"; } ?> executa.php <?php function executa($Sql){ //Testando se existe o arquivo if (file_exists("conecta.php")){ include("conecta.php"); } if (!file_exists("conecta.php")){ $msgErro = "<center><font color='#FF0000'><b>"; $msgErro .= "Não foi possível conectar ao banco de Dados<br>"; $msgErro .= "Porque não existe o arquivo 'conecta.php'."; $msgErro .= "</b></font></center>"; echo "<br><br>"; echo $msgErro; exit; } $Resultado = pg_query($conectabd,$Sql); pg_close($conectabd); return $Resultado; } ?> conecta.php <?php $conectabd = pg_connect("dbname = BD_Revista port = 5432 host = localhost user = postgres password = 159-*/rpg"); if ($conectabd) { //Caso queira Imprimir na Tela a mensagem, retirar o comentário echo "Conectado com: " . pg_host($conectabd) . "<br/> "; } else { echo pg_last_error($conectabd); exit; } ?> formconsulta.html <HTML> <HEAD> <TITLE>Formulário de Cadastro</TITLE> </HEAD> <BODY> <center> <form name = "frmConsulta" method="POST" action = "consultar.php"> Documento:<input type="text" size="20" name = "documentoid"><BR> Revista: <input type="text" size="20" name = "revistaid"><BR> Codigo da Seção:<input type="text" size="20" name = "codsecao"><BR> Documento: <input type="text" name = "documento"><BR> <input type="submit" value="Pesquisar"> </form> <center> </BODY> </HTML> consultar.php -> este arquivo está errado, preciso de uma LUZ exatamente na parte da consulta, tanto no php como no html <?php $varSQL = "select documentoid, revistaid, codsecao, documento from tb102_documento"; $varConexao = pg_connect("dbname = BD_Revista port = 5432 host = localhost user = postgres password = 159-*/rpg"); $varResultado = pg_query($varConexao,$varSQL); // $varObjeto = pg_fetch_object ($varResultado,0); if ( $varResultado ) { while ( $varLinha = pg_fetch_array($varResultado) ) { $varConteudo = base64_decode("'".$varLinha[1]."'"); $varArquivo = fopen($varLinha[0],"w"); fwrite($varArquivo,$varConteudo); fclose($varArquivo); echo " <tr> " . " <td width='50%'>" . $varLinha[0] . "</td>" . " <td width='50%'><img src='" . $varLinha[0] ."'></td>" . " </tr> "; } } else { //echo "Erro na leitura<br>"; } ?> Desde já eu agradeço a colaboração de todos...
-
Postar código completo. Utilizando o banco de dados MySql ou Postgresql. Utilizando as linguagens C ou C++. Alguém poderia postar aí um código que faça um CRUD nas tecnologias citadas acima ?
-
Não estou conseguindo resolver os seguintes problemas, poderiam me ajudar?: 1- O proprietário da empresa deseja obter constantemente um relatório que apresenta qual o veículo que foi alugado pela empresa, exibindo os dados do veículo, total de quilometragem rodada nas locações, a quantidade de locações realizadas e, por fim, uma média de quilômetros rodados a cada locação. Crie uma view para satisfazer esta necessidade 2- É necessário fazer o controle da quilometragem do veículo. Ou seja, ao final de uma locação deve ser atualizado no sistema (tabela carros) a quantidade de quilômetros que o veículo rodou. create table sedes( id numeric(10), nome varchar(50) not null, endereco varchar(50) not null, telefone varchar(20) not null, nomeGerente varchar(50) not null, multa numeric(10,2) not null, constraint pk_sedes primary key (id) ); create table classesCarro( id numeric(10), nome varchar(20) not null check(nome in('popular', 'luxo', 'super luxo')), valorDiario numeric(10,2) not null, constraint pk_classesCarro primary key (id) ); create table clientes( id numeric(10), nome varchar(50) not null, cnh varchar(20) not null, validadeCnh date not null, categoriaCnh varchar(3) not null, constraint pk_clientes primary key (id) ); create table carros( id numeric(10), placa varchar(10) not null, modelo varchar(40) not null, ano varchar(9) not null, cor varchar(20) not null, quilometragem numeric(10,2) not null, descricao varchar(100) not null, situacao varchar(30) not null check(situacao in('alugado', 'disponivel', 'fora do ponto de origem')), origemCarro numeric(10) not null, localizacaoCarro numeric(10) not null, classeCarro numeric(10) not null, constraint pk_carros primary key(id), constraint fk_carros_sedeOrigem foreign key (origemCarro) references sedes(id), constraint fk_carros_sedeLocAtual foreign key (localizacaoCarro) references sedes(id), constraint fk_carros_classe foreign key (classeCarro) references classesCarro(id) ); create table reservas( id numeric(10), diarias numeric(10) not null, dataLocacao date not null, dataRetorno date, quilometrosRodados numeric(10,2), multa numeric(10,2), situacao varchar(15) not null check(situacao in('finalizada', 'em aberto')), total numeric(10,2), carroReserva numeric(10) not null, clienteReserva numeric(10) not null, sedeLocacao numeric(10) not null, sedeDevolucao numeric(10), constraint pk_reservas primary key (id), constraint fk_reservas_sedesLocacao foreign key (sedeLocacao) references sedes(id), constraint fk_reservas_sedesDevolucao foreign key (sedeDevolucao) references sedes(id), constraint fk_reservas_carros foreign key (carroReserva) references carros(id), constraint fk_reservas_clientes foreign key (clienteReserva) references clientes(id) ); create sequence seq_sedes; create sequence seq_classes; create sequence seq_clientes; create sequence seq_carros; create sequence seq_reservas; insert into sedes values(nextval('seq_sedes'), 'A', 'Rua EFB', '123456', 'Erika', 2.00); insert into sedes values(nextval('seq_sedes'), 'B', 'Rua ITA', '654321', 'Pedro', 4.00); insert into classesCarro values(nextval('seq_classes'), 'popular', 30.00); insert into classesCarro values(nextval('seq_classes'), 'super luxo', 90.00); insert into clientes values(nextval('seq_clientes'), 'Allan', '753951', '2020-12-03', 'AB'); insert into clientes values(nextval('seq_clientes'), 'Augusto', '951753', '2020-11-10', 'AB'); insert into carros values(nextval('seq_carros'), 'ABC-123', 'HB20', '2016', 'Branco', 120.00, 'Carro cheiroso', 'disponivel',(select id from sedes where nome = 'A'), (select id from sedes where nome = 'A'), (select id from classesCarro where nome = 'popular')); insert into carros values(nextval('seq_carros'), 'CBA-321', 'Mercedes Benz', '2017', 'Preto', 400.00, 'Carro banco de couro', 'disponivel', (select id from sedes where nome = 'B'), (select id from sedes where nome = 'B'), (select id from classesCarro where nome = 'super luxo')); insert into reservas values(nextval('seq_reservas'), 2, '2017-11-08', '2017-11-10', 20.00, 0, 'finalizada', 200.00, (select id from carros where modelo = 'HB20'), (select id from clientes where nome = 'Allan'), (select id from sedes where nome = 'A'), (select id from sedes where nome = 'A')); insert into reservas values(nextval('seq_reservas'), 4, '2017-11-08', '2017-11-12', 20.00, 0, 'finalizada', 600.00, (select id from carros where modelo = 'Mercedes Benz'), (select id from clientes where nome = 'Augusto'), (select id from sedes where nome = 'B'), (select id from sedes where nome = 'B'));
-
Ola, Preciso converter um valor : $1,500,35 padrão americano , para R$ 1.500,35 padrão brasileiro, porem a linguagem usada no banco e americana, e as funções que conheço só convertem o valor para a linguagem atual do banco, alguém conhece alguma forma de fazer isso?
-

Criar Campo para Pesquisa e Inserir dados Tabela em Campo de Texto
uma questão postou Caio Biesek Java
Boa Tarde Como posso criar um comando para pesquisar um item no banco de dados, e inserir esses dados em um Campo de Texto NetBeans Por exemplo Tabela: Codigo - Data - Venda - Valor Quero digitar o Codigo, clicar em Pesquisar e com isso inserir todas as outras informacoes da tabela nos campos de textos localizados abaixo (Campo Texto) Valor Venda (Campo Texto) Data Como realizo este codigo? Programa Java NetBeans Banco PostgreSQL Tentei realizar o Seguinte Codigo, Utilizando como base o codigo criado para salvar vendas. mas não funcionou Tela Programa - Inserir codigo neste Campo e pesquisar os demais itens public void alterarVenda() { String sql = "Select *from janeiro where codigo like `%" + txtcodigoalterar + "%" ; try { pst = conecta.prepareStatement(sql); // pst.setInt(1, Integer.parseInt(txtcodigoalterar.getText())); pst.setString(1, txtData.getText()); pst.setString(2, txtCliente.getText()); pst.setDouble(3, Double.parseDouble(txtValorVenda.getText())); pst.setInt(4, Integer.parseInt(txtAbacaxi.getText())); pst.setInt(5, Integer.parseInt(txtAbacaxiHortela.getText())); pst.setInt(6, Integer.parseInt(txtAcai.getText())); pst.setInt(7, Integer.parseInt(txtAcerola.getText())); pst.setInt(8, Integer.parseInt(txtAcerolaLaranja.getText())); pst.setInt(9, Integer.parseInt(txtAmora.getText())); pst.setInt(10, Integer.parseInt(txtCaja.getText())); pst.setInt(11, Integer.parseInt(txtCaju.getText())); pst.setInt(12, Integer.parseInt(txtCoco.getText())); pst.setInt(13, Integer.parseInt(txtCupuacu.getText())); pst.setInt(14, Integer.parseInt(txtGoiaba.getText())); pst.setInt(15, Integer.parseInt(txtGraviola.getText())); pst.setInt(16, Integer.parseInt(txtLaranja.getText())); pst.setInt(17, Integer.parseInt(txtLimao.getText())); pst.setInt(18, Integer.parseInt(txtMamao.getText())); pst.setInt(19, Integer.parseInt(txtMamaoMaracuja.getText())); pst.setInt(20, Integer.parseInt(txtManga.getText())); pst.setInt(21, Integer.parseInt(txtMaracuja.getText())); pst.setInt(22, Integer.parseInt(txtMelao.getText())); pst.setInt(23, Integer.parseInt(txtMisto.getText())); pst.setInt(24, Integer.parseInt(txtMorango.getText())); pst.setInt(25, Integer.parseInt(txtPessego.getText())); pst.setInt(26, Integer.parseInt(txtTangerina.getText())); pst.setInt(27, Integer.parseInt(txtUva.getText())); pst.execute(); JOptionPane.showMessageDialog(null, "Alterado com Sucesso", "alterado com Sucesso", JOptionPane.INFORMATION_MESSAGE); } catch (SQLException error) { JOptionPane.showMessageDialog(null, error); } } Estou precisando resolver este problema, alguém consegue me ajudar ? Desde já agradeço a atenção de todos -
Prezados, bom dia! Estou iniciando com o postgresql e me surgiu uma demanda para realizar um dump e um restore, até aí tudo bem, porém ao executar o comando me retorna a seguinte mensagem: FATAL: nenhuma entrada no pg_hba.conf para máquina "[local]", usuário "postgres", banco de dados "banco_de_dados", SSL desabilitado E o Dump não é executado. Já verifiquei no arquivo pg_hba.conf e a máquina local está com permissão trust e já executei o reload no postgres. Será que alguém pode me dar uma luz? Não faço ideia do que seja. Desde já agradeço a todos.
-
 Um cliente meu me pediu para inserir cerca de 15 mil registros de pacientes (de um programa antigo) em uma tabela num banco de dados do PostgreSQL do programa novo que ele usa. Para fazer isso eu preciso conseguir abrir o banco de dados dele no meu computador mas não faço ideia de como fazer isso. Eu fiz uma cópia do que eu acho que seja o banco de dados dele (uma série de arquivos nomeados com números) no caminho "PostgreSQL\9.4\data\base" totalizando quase 1GB. Eu já instalei o PostgreSQL no meu computador e fiz a tola tentativa de sobrescrever a minha pasta "base" com os arquivos dele, mas obviamente não funcionou (eu já esperava isso). Como eu devo proceder nesse caso? Obrigado!
Um cliente meu me pediu para inserir cerca de 15 mil registros de pacientes (de um programa antigo) em uma tabela num banco de dados do PostgreSQL do programa novo que ele usa. Para fazer isso eu preciso conseguir abrir o banco de dados dele no meu computador mas não faço ideia de como fazer isso. Eu fiz uma cópia do que eu acho que seja o banco de dados dele (uma série de arquivos nomeados com números) no caminho "PostgreSQL\9.4\data\base" totalizando quase 1GB. Eu já instalei o PostgreSQL no meu computador e fiz a tola tentativa de sobrescrever a minha pasta "base" com os arquivos dele, mas obviamente não funcionou (eu já esperava isso). Como eu devo proceder nesse caso? Obrigado! -
Boa tarde, pessoal! É o seguinte, eu criei uma trigger para alterar alguns campos dentro da própria tabela da trigger para evitar retrabalho na codificação, até aí tudo bem. Nesta trigger eu tenho uma função que retorna a chave primária de uma tabela nossa para fins de logs, nesse caso, para saber que realizou o cancelamento, mas ao atribuir o valor que essa função retorna para o campo da tabela da trigger, o campo continua nulo (MAS ELE RETORNA!, Fiz um teste inserindo o registro que deveria ser atribuindo, inserindo-o numa tabela de teste, e foi inserido com sucesso!). Segue a trigger: DECLARE vidlogorigem integer; vgeralog boolean = false; BEGIN IF tg_op = 'UPDATE' THEN vgeralog = (OLD.sit <> 'CC') AND (NEW.sit = 'CC'); ELSEIF tg_op = 'INSERT' THEN vgeralog = NEW.sit = 'CC'; END IF; IF vgeralog THEN vidlogorigem = (select getidlogorigem()); insert into teste(id) values (vidlogorigem); NEW.teste = vidlogorigem; NEW.datacancel = clock_timestamp(); END IF; RETURN NEW; END; A função "getidlogorigem" é a que me retorna a chave primária duma tabela de usuários. Eu utilizo isto em outros lugares que funcionam tranquilamente. Obrigado!
-
Olá a todos, sou novo no fórum e na verdade esse é o primeiro post que faço em um fórum. Trabalho em uma empresa de plano de assistência médico/hospitalar e estou desenvolvendo um sistema para controle de guias de pedidos de exames ambulatoriais e consultas médicas. Quando alguma dessas guias está incorreta, devolvo ela para o prestador de serviço que realizou a consulta ou exame. O objetivo do sistema é automatizar esse controle. Na parte de programação está tudo encaminhando bem. O problema é que tenho uma dúvida no select do banco PostgreSQL. Dentre todas as tabelas tenho uma tabela chamada "prestador" onde é salvo todos os médicos, laboratórios, hospitais, etc. E tem uma tabela que chama "guia" é salvo as guias para serem devolvidas. Na tabela "guia" tenho dois campos, "solicitante_guia" e "executante_guia" que são chaves estrangeiras da tabela "prestador", por exemplo, na guia vou preencher qual prestador solicitou o exame, e qual prestador realizou(executou) o exame. No insert não tive problemas, tive problema no select dessas informações. Segue abaixo a tabela: CREATE TABLE guia ( id_guia serial NOT NULL, senha_guia integer, numero_guia varchar, grupo_guia integer, carteira_guia varchar, beneficiario_guia varchar, parecer_guia integer, solicitante_guia integer, executante_guia integer, atendimento_guia integer, situacao_guia integer, status_guia integer NOT NULL, obs_guia varchar, CONSTRAINT pk_guia PRIMARY KEY (id_guia), CONSTRAINT fk_guia_grupo FOREIGN KEY (grupo_guia) REFERENCES grupo (id_grupo), CONSTRAINT fk_guia_parecer FOREIGN KEY (parecer_guia) REFERENCES parecer (id_parecer), CONSTRAINT fk_guia_solicitante FOREIGN KEY (solicitante_guia) REFERENCES prestador (id_prestador), CONSTRAINT fk_guia_executante FOREIGN KEY (executante_guia) REFERENCES prestador (id_prestador), CONSTRAINT fk_guia_atendimento FOREIGN KEY (atendimento_guia) REFERENCES atendimento (id_atendimento), CONSTRAINT fk_guia_situacao FOREIGN KEY (situacao_guia) REFERENCES situacao (id_situacao), CONSTRAINT fk_guia_status FOREIGN KEY (status_guia) REFERENCES status (id_status) ); SELECT * FROM guia INNER JOIN grupo ON grupo.id_grupo = guia.grupo_guia INNER JOIN parecer ON parecer.id_parecer = guia.parecer_guia ->->-> INNER JOIN prestador ON prestador.id_prestador = guia.solicitante_guia ->->-> INNER JOIN prestador ON prestador.id_prestador = guia.executante_guia INNER JOIN atendimento ON atendimento.id_atendimento = guia.atendimento_guia INNER JOIN situacao ON situacao.id_situacao = guia.situacao_guia INNER JOIN status ON status.id_status = guia.status_guia ERRO DO SELECT ERROR: table name "prestador" specified more than once ********** Error ********** ERROR: table name "prestador" specified more than once SQL state: 42712 O que estou fazendo de errado? Como podem ver sou muito leigo com relação a banco de dados (minha única DP na Faculdade rsrsrs). Desde já, muito obrigado.
-
O meu sistema funciona da seguinte maneira: Tenho 1517 sensores que armazenam em cada dia do ano, uma certa precipitação que é medida de três em três horas durante todo o dia. Tenho uma tabela chamada pontos que tem as seguintes colunas: gid (que é a chave primária de cada sensor), latitude, longitude. E tenho uma outra tabela chamada historico que tem as seguintes colunas: id (que é a chave primária de cada historico), datah, horah, precipitacaoh, gidgeo_fk (que é a chave estrangeira que represente os sensores). Fiz um script em python para armazenar cada sensor em um arquivo chamado sensor.csv, que armazena também cada hora distinta em outro arquivo chamado data.csv, e armazena também a precipitação e hora em arquivos separados. Depois crio um arquivo que faz um relacionamento entre todos estes pontos. O problema é que são 1517 sensores, e eu estava testando isso pra ver se dava tudo certo para 1 sensor apenas, ou seja, ele pega um sensor e armazena todo o histórico deste sensor em arquivos, juntamente com os relacionamentos, mas isso está demorando 192 minutos mais ou menos, PARA APENAS UM SENSOR, pra fazer isso para 1517 sensores iria levar mais de 200 dias! Gostaria que alguém me ajudasse a diminuir este tempo drasticamente, sem ter que mexer em index e etc. Creio que seja o jeito que estou programando o meu script, mas não sei onde estou programando errado. Alguém pode me ajudar? Abaixo está o código do meu script. import psycopg2 import csv conn = psycopg2.connect("\ dbname='bdTrmmTest'\ user='postgres'\ host='127.0.0.1'\ password='1234'\ "); #input() csv_sensor = open('sensor.csv',"w") csv_data = open('data.csv',"w") csv_hora = open('hora.csv',"w") csv_precipitacao = open('precipitacao.csv',"w") csv_rels = open('rels.csv',"w") labelSensor = 'Sensor' labelData = 'Data' labelHora = 'Hora' labelPrecip = 'Precipitacao' labelAS = 'AS' labelEM = 'EM' labelREGISTROU = 'REGISTROU' contGeral = 0 c = conn.cursor() c1 = conn.cursor() c2 = conn.cursor() c3 = conn.cursor() writer = csv.writer(csv_sensor) writer2 = csv.writer(csv_data) writer3 = csv.writer(csv_hora) writer4 = csv.writer(csv_precipitacao) writer5 = csv.writer(csv_rels) writer.writerow(('name:ID', 'IDPostgres', 'latitude', 'longitude', ':LABEL')) writer2.writerow(('data:ID','vdata',':LABEL')) writer3.writerow(('hora:ID','vhora',':LABEL')) writer4.writerow(('precip:ID','valor',':LABEL')) writer5.writerow((':START_ID',':END_ID',':TYPE')) c.execute("SELECT DISTINCT gid, latitude, longitude FROM pontos LIMIT 1") c1.execute("SELECT DISTINCT datah FROM historico") c3.execute("SELECT DISTINCT horah FROM historico") records = c.fetchall() records1 = c1.fetchall() records3 = c3.fetchall() for contSensor in records: print("Escrevendo sensor %d"%(contSensor[0])) writer.writerow((contGeral,contSensor[0], contSensor[1], contSensor[2], labelSensor)) print("Sensor %d escrito"%(contSensor[0])) contSensorFlag = contGeral contGeral += 1 for contReg in records1: contData = contGeral print("Escrevendo data %s"%(contReg[0])) writer2.writerow((contGeral, contReg[0], labelData)) print("Data %s escrita"%(contReg[0])) #escreve relacionamento entre sensor e data print("Escrevendo relacionamento entre sensor %d e data %s"%(contSensor[0],contReg[0])) writer5.writerow((contSensorFlag,contData, labelEM)) print("Relacionamento entre sensor %d e data %s escrito"%(contSensor[0],contReg[0])) contGeral += 1 for contReg3 in records3: c2.execute("SELECT precipitacaoh FROM historico WHERE gidgeo_fk = %d AND datah = '%s' AND horah = %d"%(contSensor[0],contReg[0],contReg3[0])) records2 = c2.fetchall() contHora = contGeral print("Escrevendo hora %d"%(contReg3[0])) writer3.writerow((contGeral, contReg3[0], labelHora)) print("Hora %d escrita"%(contReg3[0])) contGeral += 1 #escreve relacionamento entre data e hora print("Escrevendo relacionamento entre data %s e hora %d"%(contReg[0],contReg3[0])) writer5.writerow((contData,contHora, labelAS)) print("Relacionamento entre data %s e hora %d escrito"%(contReg[0],contReg3[0])) for contReg2 in records2: contPrecip = contGeral print("Escrevendo precipitacao %s"%(contReg2[0])) writer4.writerow((contGeral,contReg2[0], labelPrecip)) print("Precipitacao %s escrita"%(contReg2[0])) #escreve relacionamento entre hora e precipitacao print("Escrevendo relacionamento entre hora %d e precipitacao %s"%(contReg3[0],contReg2[0])) writer5.writerow((contHora,contPrecip, labelREGISTROU)) print("Relacionamento entre hora %d e precipitacao %s escrito"%(contReg3[0],contReg2[0])) contGeral += 1 csv_sensor.close() csv_data.close() csv_hora.close() csv_precipitacao.close() csv_rels.close() print(open('sensor.csv', 'rt').read())
-
O meu sistema funciona da seguinte maneira: Tenho 1517 sensores que armazenam em cada dia do ano, uma certa precipitação que é medida de três em três horas durante todo o dia. Tenho uma tabela chamada pontos que tem as seguintes colunas: gid (que é a chave primária de cada sensor), latitude, longitude. E tenho uma outra tabela chamada historico que tem as seguintes colunas: id (que é a chave primária de cada historico), datah, horah, precipitacaoh, gidgeo_fk (que é a chave estrangeira que represente os sensores). Fiz um script em python para armazenar cada sensor em um arquivo chamado sensor.csv, que armazena também cada hora distinta em outro arquivo chamado data.csv, e armazena também a precipitação e hora em arquivos separados. Depois crio um arquivo que faz um relacionamento entre todos estes pontos. O problema é que são 1517 sensores, e eu estava testando isso pra ver se dava tudo certo para 1 sensor apenas, ou seja, ele pega um sensor e armazena todo o histórico deste sensor em arquivos, juntamente com os relacionamentos, mas isso está demorando 192 minutos mais ou menos, PARA APENAS UM SENSOR, pra fazer isso para 1517 sensores iria levar mais de 200 dias! Gostaria que alguém me ajudasse a diminuir este tempo drasticamente, sem ter que mexer em index e etc. Creio que seja o jeito que estou programando o meu script, mas não sei onde estou programando errado. Alguém pode me ajudar? Abaixo está o código do meu script. import psycopg2 import csv conn = psycopg2.connect("\ dbname='bdTrmmTest'\ user='postgres'\ host='127.0.0.1'\ password='1234'\ "); #input() csv_sensor = open('sensor.csv',"w") csv_data = open('data.csv',"w") csv_hora = open('hora.csv',"w") csv_precipitacao = open('precipitacao.csv',"w") csv_rels = open('rels.csv',"w") labelSensor = 'Sensor' labelData = 'Data' labelHora = 'Hora' labelPrecip = 'Precipitacao' labelAS = 'AS' labelEM = 'EM' labelREGISTROU = 'REGISTROU' contGeral = 0 c = conn.cursor() c1 = conn.cursor() c2 = conn.cursor() c3 = conn.cursor() writer = csv.writer(csv_sensor) writer2 = csv.writer(csv_data) writer3 = csv.writer(csv_hora) writer4 = csv.writer(csv_precipitacao) writer5 = csv.writer(csv_rels) writer.writerow(('name:ID', 'IDPostgres', 'latitude', 'longitude', ':LABEL')) writer2.writerow(('data:ID','vdata',':LABEL')) writer3.writerow(('hora:ID','vhora',':LABEL')) writer4.writerow(('precip:ID','valor',':LABEL')) writer5.writerow((':START_ID',':END_ID',':TYPE')) c.execute("SELECT DISTINCT gid, latitude, longitude FROM pontos LIMIT 1") c1.execute("SELECT DISTINCT datah FROM historico") c3.execute("SELECT DISTINCT horah FROM historico") records = c.fetchall() records1 = c1.fetchall() records3 = c3.fetchall() for contSensor in records: print("Escrevendo sensor %d"%(contSensor[0])) writer.writerow((contGeral,contSensor[0], contSensor[1], contSensor[2], labelSensor)) print("Sensor %d escrito"%(contSensor[0])) contSensorFlag = contGeral contGeral += 1 for contReg in records1: contData = contGeral print("Escrevendo data %s"%(contReg[0])) writer2.writerow((contGeral, contReg[0], labelData)) print("Data %s escrita"%(contReg[0])) #escreve relacionamento entre sensor e data print("Escrevendo relacionamento entre sensor %d e data %s"%(contSensor[0],contReg[0])) writer5.writerow((contSensorFlag,contData, labelEM)) print("Relacionamento entre sensor %d e data %s escrito"%(contSensor[0],contReg[0])) contGeral += 1 for contReg3 in records3: c2.execute("SELECT precipitacaoh FROM historico WHERE gidgeo_fk = %d AND datah = '%s' AND horah = %d"%(contSensor[0],contReg[0],contReg3[0])) records2 = c2.fetchall() contHora = contGeral print("Escrevendo hora %d"%(contReg3[0])) writer3.writerow((contGeral, contReg3[0], labelHora)) print("Hora %d escrita"%(contReg3[0])) contGeral += 1 #escreve relacionamento entre data e hora print("Escrevendo relacionamento entre data %s e hora %d"%(contReg[0],contReg3[0])) writer5.writerow((contData,contHora, labelAS)) print("Relacionamento entre data %s e hora %d escrito"%(contReg[0],contReg3[0])) for contReg2 in records2: contPrecip = contGeral print("Escrevendo precipitacao %s"%(contReg2[0])) writer4.writerow((contGeral,contReg2[0], labelPrecip)) print("Precipitacao %s escrita"%(contReg2[0])) #escreve relacionamento entre hora e precipitacao print("Escrevendo relacionamento entre hora %d e precipitacao %s"%(contReg3[0],contReg2[0])) writer5.writerow((contHora,contPrecip, labelREGISTROU)) print("Relacionamento entre hora %d e precipitacao %s escrito"%(contReg3[0],contReg2[0])) contGeral += 1 csv_sensor.close() csv_data.close() csv_hora.close() csv_precipitacao.close() csv_rels.close() print(open('sensor.csv', 'rt').read())
-
 Olá Senhores, tudo bem com vocês ?Bom ,sou leigo em SQL e estou com um problema que é o seguinte:Estou usando o PostGreSQLTennho uma tabela chamada OfMessageArchive , contendo a coluna FROMJIDNessa tabela tenho diversos registros que estão como joao@hotmail.com , maria@bol.com.br , marcos@gmail.com e por aí vai.Acredito que uns 15 dominios de e-mails diferentes. Não sei quais são todos eles.Tendo essas informações preciso alterar por exemplo tudo que esteja como @hotmail.com para @empresa.com.br , tudo o que esteja como @bol.com.br , para @empresa.com.br e por aí vai , deixando tudo como joao@empresa.com.br , maria@empresa.com.br , marcos@empresa.com.br e por aí vai.Preciso então de 2 comandos , e essas são as minhas dúvidas:1 - Qual comando eu comando eu consigo listar todos os registros nessa coluna que estão com @ alguma coisa , sem ter que repeti-los ( estamos falando de quase 45.000 registros) ? Exemplo:Após executar o comando ele mostra que na coluna FROMJID tem os dominios:@bol.com.br @hotmail.com@gmail.com ??????????2 - Eu sabendo quais são os dominios de e-mail que estão cadastrados na coluna FROMJID da tabela OfMessageArchive , qual o comando eu uso para substiruir todos esses dominios @bol.com.br , @gmail.com e por aí vai , por @empresa.com.br , deixando por exemplo joao@bol.com.br para joao@empresa.com.br ?Muito obrigado galera
Olá Senhores, tudo bem com vocês ?Bom ,sou leigo em SQL e estou com um problema que é o seguinte:Estou usando o PostGreSQLTennho uma tabela chamada OfMessageArchive , contendo a coluna FROMJIDNessa tabela tenho diversos registros que estão como joao@hotmail.com , maria@bol.com.br , marcos@gmail.com e por aí vai.Acredito que uns 15 dominios de e-mails diferentes. Não sei quais são todos eles.Tendo essas informações preciso alterar por exemplo tudo que esteja como @hotmail.com para @empresa.com.br , tudo o que esteja como @bol.com.br , para @empresa.com.br e por aí vai , deixando tudo como joao@empresa.com.br , maria@empresa.com.br , marcos@empresa.com.br e por aí vai.Preciso então de 2 comandos , e essas são as minhas dúvidas:1 - Qual comando eu comando eu consigo listar todos os registros nessa coluna que estão com @ alguma coisa , sem ter que repeti-los ( estamos falando de quase 45.000 registros) ? Exemplo:Após executar o comando ele mostra que na coluna FROMJID tem os dominios:@bol.com.br @hotmail.com@gmail.com ??????????2 - Eu sabendo quais são os dominios de e-mail que estão cadastrados na coluna FROMJID da tabela OfMessageArchive , qual o comando eu uso para substiruir todos esses dominios @bol.com.br , @gmail.com e por aí vai , por @empresa.com.br , deixando por exemplo joao@bol.com.br para joao@empresa.com.br ?Muito obrigado galera -
Ola, sou iniciante em banco de dados, estou no primeiro ano da faculdade de tecnologia da informação, estou com uma dúvida, tenho um banco de dados aqui que foi feito em access, eu consigo até exportar ele pra umas tabelas em excel, mas eu queria um sistema de gerenciamento de banco de dados, que tivesse uma interface mais amigável, alguma coisa que pudesse acessar esse banco de dados que eu tenho aqui, mas que usuários normais pudessem acessar também, porque é meio complexo ficar consultando os dados pelo access, será que o PostgreSQL permite usuários comuns acessarem este banco de dados? ou existe alguma outra ferramenta gratuita para isso? desde já agradeço a ajuda !
-
Pessoal!! Eu preciso de uma ajudinha pra fazer a questão de número 29, seria ótimo se alguém me ajudasse pois estou preso nesta questao tem bastante tempo no meu treinamento! Estou usando o programa PostgreSQL em Linux. OBS: O HD da tabela PC esta em chacacter, terá de usar o cast pra transferi-lo pra double precision e calcular a media! PLS! Me ajudem!



-
Olá pessoal! Sou estudante de ADS e tenho uma dúvida: o PostgreSQL permite a criação de webservice dentro de sua estrutura? Em Oracle, por exemplo, temos o DB Web Service, onde é possível criar um Web Service dentro do SGBD (o que ao meu ver dispensaria o uso de uma linguagem de programação como Java, PHP ou C# para conectar no banco de dados, realizar as operações e mandar um retorno para a aplicação). Obrigado!
-
Olá a todos, quem poder ajudar, eu gostaria de indicação de um software (para sistema Windows) para gerenciar o banco de dados Postgres que tenha a função na qual possa se trabalhar com dados do tipo TYPE e que possa visualiza-los em janela(modo gráfico).
-
Olá scriptbrasil. Venho aqui na esperança de encontrar ajuda em mais um local, estou a tempos rodando por comunidades internacionais e nada. Há algum tempo atrás eu comecei a trabalhar com o PostgreSQL 9.5.3, e venho encontrando dificuldades em relação a um problema relativo a privilégios (acredito). Estou montando um sistema simples para testes e aprendizado, um e-commerce simples. Este sistema está para ser desenvolvido em Java (eu ainda estou montando o banco de dados). Bem, sem mais papo-furado... Inicialmente eu resolvi definir no sistema 3 tipos de usuários (todos são contas de usuário com LOGIN): dbadiretor: Este cargo/papel (role) tem a função de agir como super usuário no banco de dados. dbagerente: Este cargo tem permissões CRUD relativas aos objetos presentes no banco de dados, não em relação a registros. Ou seja, este cargo pode criar, modificar, alterar, e/ou apagar objetos do banco de dados, tal como tabelas, funções, triggers, e etc. clisistema:Esta cargo representa uma conexão para a aplicação cliente, o sistema que se conectará e utilizará o banco de dados. Este papel/cargo pode realizar operações CRUD nos registros das tabelas, mas não operações CRUD nos objetos do banco de dados. Em resumo, este cargo pode pesquisar registros, mas não pode alterar as estruturas do banco de dados. Além disso, para algumas tabelas maiores limitações (filtros) são adicionados, impedindo que este cargo realize todas as operações CRUD, mas sim, só algumas. Eu não sou DBA (apesar de modelador de dados com DER), sou desenvolvedor Java, e não sei se separar e organizar estes tipos de cargos é aplicável e/ou recomendado. Mas enfim... Como sou novo no assunto, resolvi criar e organizar arquivos de passos lógicos para a criação e preparação do banco de dados. Cada arquivo representa uma etapa na preparação do banco de dados. No meio da execução destes arquivos, ao distribuir privilégios para os cargos (contas, no caso) criados, eu me deparei com um erro o qual eu não estou conseguindo resolver de forma alguma. Estou realmente perdendo o juízo com isso (estou utilizando o pgAdmin 3): ERROR: permission denied for relation tb_tabelas CONTEXT: SQL statement "SELECT 1 FROM ONLY "regrast"."tb_tabelas" x WHERE "tba_id" OPERATOR(pg_catalog.=) $1 FOR KEY SHARE OF x" ********** Error ********** ERROR: permission denied for relation tb_tabelas SQL state: 42501 Mesmo utilizando o super usuário postgresql ou o super usuário criado dbadiretor eu me deparo com este erro. Eu não estou realizando esta declaração SQL, pelo menos, talvez, não diretamente. Como super usuário, acredito ter permissão para realizar tal operação, mas parando para olhar, acho que o erro diz que a permissão não é dada devido a uma relação existente pela tabela tb_tabelas. Contudo, mesmo assim, não vejo o que há de errado se paro para observar o código SQL. Para que vocês vejam completamente e com precisão o que eu estou fazendo (de errado) do começo ao fim, e possam ao mesmo tempo observar o meu código, eu gravei um vídeo da tela de meu computador com duração de 4 minutos, aproximadamente. Por favor, se você, leitor, não se incomodar, dê uma olhada: http://sendvid.com/30c2s87s Observe que no vídeo eu encontro-me criando e preparando um banco de dados do começo ao fim. Tudo o que eu faço é executar arquivos com instruções SQL, como já dito. Tenho desconfianças no momento que as instruções "REVOKE ..." são feitas, pois quando comento-as, tudo parece funcionar adequadamente, no sentido que, eu posso inserir novos registros nas tabelas. Caso qualquer informação adicional seja necessária para melhor compreensão, ficarei feliz em coloca-la a disposição aqui. Basta pedir. De outra forma, se o vídeo não for aceitável por qualquer motivo que seja, eu posso removê-lo e adicionar o resto das informações necessárias aqui. Agradeço de antemão pela atenção, pela disponibilidade, e pelo conhecimento doado. Qualquer dica, crítica, sugestão, melhoria, suspeita em relação ao código são bem vindas.
-
 Olá :) Bem, antes de tudo, sou uma novata. Estou na faculdade e tenho um projeto de estágio cujo propósito é migrar a estrutura e os dados de um banco de dados Firebird para um PostgreSQL. Já consegui construir as tabelas, chaves, índices, views no novo banco PostgreSQL. Agora me deparo com os stored procedures do Firebird, eles são 140. Preciso convertê-los em functions no PostgreSQL. Minha dúvida é: existe alguma ferramenta que faça essa conversão? Já testei algumas ferramentas de migração, como DBTools Manager Professional, Full Convert e PostgreSQL Database Converter, mas nenhum deles converte procedures. Gostaria de encontrar uma ferramenta porque tenho pouco tempo para fazer essa conversão toda à mão, e ainda nem cheguei nos triggers... Desde já agradeço.
Olá :) Bem, antes de tudo, sou uma novata. Estou na faculdade e tenho um projeto de estágio cujo propósito é migrar a estrutura e os dados de um banco de dados Firebird para um PostgreSQL. Já consegui construir as tabelas, chaves, índices, views no novo banco PostgreSQL. Agora me deparo com os stored procedures do Firebird, eles são 140. Preciso convertê-los em functions no PostgreSQL. Minha dúvida é: existe alguma ferramenta que faça essa conversão? Já testei algumas ferramentas de migração, como DBTools Manager Professional, Full Convert e PostgreSQL Database Converter, mas nenhum deles converte procedures. Gostaria de encontrar uma ferramenta porque tenho pouco tempo para fazer essa conversão toda à mão, e ainda nem cheguei nos triggers... Desde já agradeço. -
 Boa Tarde a todos, sou iniciante e estou com um problema no qual não consigo resolver. Não encontrei nenhum post com a dúvida em especifico, então estou recorrente ao fórum. Estou configurando um servidor de banco de dados, neste caso CentOS 7 + PostgreSql 9.3. Após deixar ele funcionando no Linux apareceu o desafio. As máquinas do windows não enxergam os bancos do servidor. No servidor, já alterei os arquivos pg_hba.conf (host all all 0.0.0.0/0 trust) Também alterei postgresql.conf (Tanto habilitei a porta 5432 e listen_addresses="*") No Pgadmin no Windows, crio meu server, em host defino o ip do servidor, em meu caso \\192.168.200.230, ele entende e conecta. No entanto ele não lê os BDs do meu servidor, ele apenas está fazendo um espécie de "conexão local", ignorando o ip do servidor e os seus BDs. Em todas as maquinas o problema foi o mesmo. É obvio que estou fazendo algo errado, mas preciso de ajudar apra descobrir. Eu preciso que todas as minhas maquinas Windows,consultem e alterem o BD dentro da maquina Linux. Alguém tem ideia de como posso proceder? Não sou da área, mas sempre tento aprender algo a respeito, por isso se disse qualquer bobagem, desconsiderem. Muito obrigado desde já!! Att, Vinicius
Boa Tarde a todos, sou iniciante e estou com um problema no qual não consigo resolver. Não encontrei nenhum post com a dúvida em especifico, então estou recorrente ao fórum. Estou configurando um servidor de banco de dados, neste caso CentOS 7 + PostgreSql 9.3. Após deixar ele funcionando no Linux apareceu o desafio. As máquinas do windows não enxergam os bancos do servidor. No servidor, já alterei os arquivos pg_hba.conf (host all all 0.0.0.0/0 trust) Também alterei postgresql.conf (Tanto habilitei a porta 5432 e listen_addresses="*") No Pgadmin no Windows, crio meu server, em host defino o ip do servidor, em meu caso \\192.168.200.230, ele entende e conecta. No entanto ele não lê os BDs do meu servidor, ele apenas está fazendo um espécie de "conexão local", ignorando o ip do servidor e os seus BDs. Em todas as maquinas o problema foi o mesmo. É obvio que estou fazendo algo errado, mas preciso de ajudar apra descobrir. Eu preciso que todas as minhas maquinas Windows,consultem e alterem o BD dentro da maquina Linux. Alguém tem ideia de como posso proceder? Não sou da área, mas sempre tento aprender algo a respeito, por isso se disse qualquer bobagem, desconsiderem. Muito obrigado desde já!! Att, Vinicius



















